taketea2018 が 2026年02月24日15時30分53秒 に編集
初版
タイトルの変更
データサイエンス入門 第5回 webスクレイピング その1
タグの変更
データサイエンス
Python
webスクレイピング
GoogleColaboratory
記事種類の変更
セットアップや使用方法
本文の変更
# データサイエンス入門 AIプログラミングで学ぶデータサイエンス ## 第5回 webスクレイピング その1 ~簡単なwebページのスクレイピング~ webスクレイピングとは・・・ 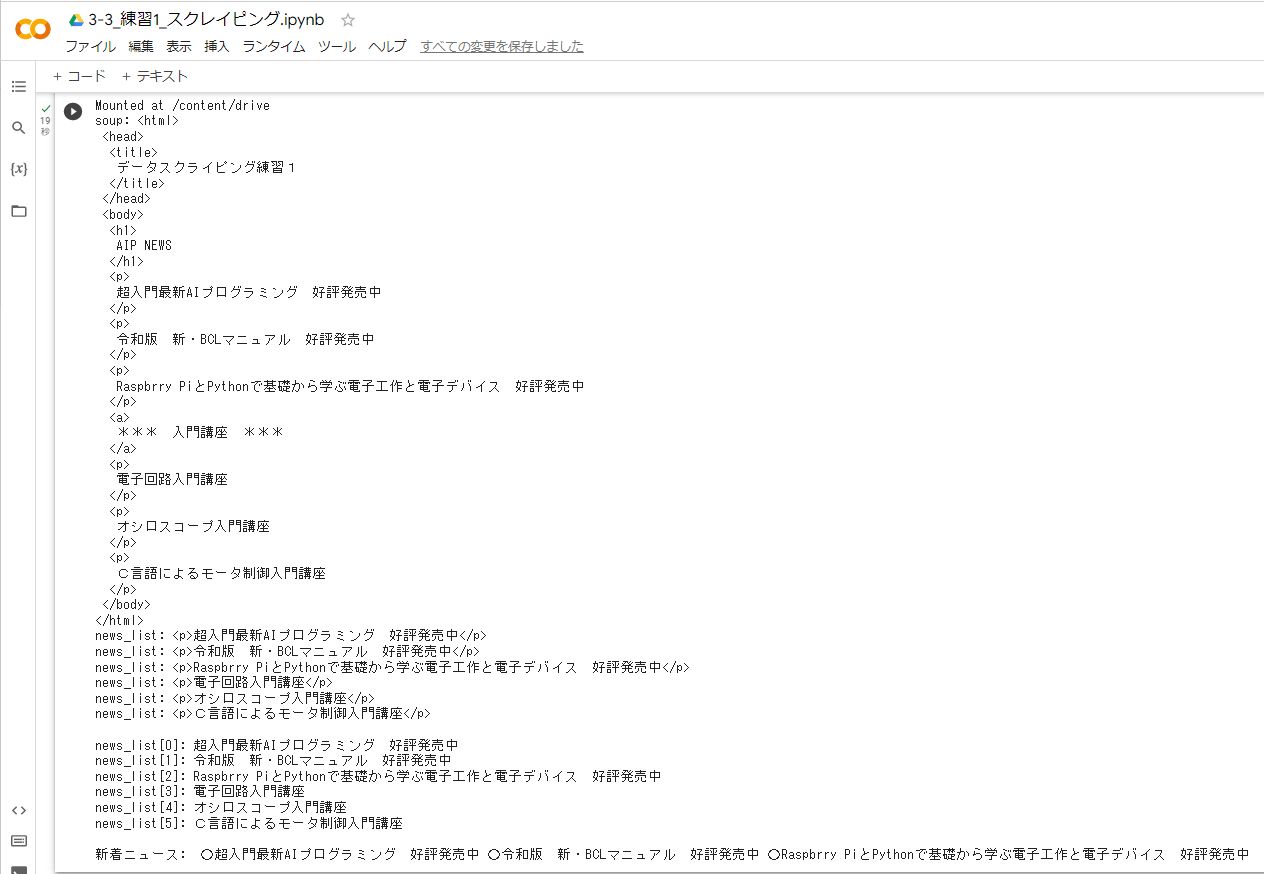 webスクレイピングという単語を耳にしたことがありますか。なんだか怪しい響きを持つ意味深な言葉だと思っている方が多いかもしれませんね。 webページはhtmlやcss、javaスクリプトなど様々な記述言語により構成されています。華やかでおしゃれなwebページを構築するためにずいぶん複雑になっています。 webスクレイピングとは、webを構成するhtmlなどのwebページ記述言語から必要な内容だけを抜き出す技術のことをいいます。 世界中に存在する様々なwebページから必要な情報を集める際にもwebスクレイピングが用いられます。 ニュースサイトからニュースの見出しだけをスクレイピングし、別のwebページでまとめて表示していることを見かけます。 これがいわゆるまとめサイトです。まとめサイトで引用しているニュース見出しにもちゃんと著作権があります。そのために、webスクレイピングを行う際にはそのwebページでスクレイピング可能かどうかを確認する必要があります。 ここではPythonを用いてwebスクレイピングを行うテクニックを筆者が用意したhtmlファイルにより構築された疑似webページ上で練習します。最後に実存するwebサイトで実践します。 ## 〇紹介動画は下記URLよりご視聴ください。 https://youtu.be/ksTOtPSXlpk ## 〇スライド形式pdf解説書です。 https://drive.google.com/file/d/1ivICMa4Lj_E0oRdHtOUmsVFq849JfssC/view?usp=drive_link ## 〇演習用webページ ren1_html.html(第5回目用) https://drive.google.com/file/d/1gOf56S2u9_e5Msn55pF4PveI10cfF_p9/view?usp=drive_link ren2_html.html(第6回目用) https://drive.google.com/file/d/1Z84EAeOPikzAdn1W348RIb3DqUW1XYw6/view?usp=drive_link ## 〇サンプルプログラム 実行にはren1_html.htmlが必要です。 ``` !pip install requests ``` ``` from bs4 import BeautifulSoup #BeautifulSoup取り込み from google.colab import drive #googleドライブ初期化 drive.mount('/content/drive') # トップページ情報を取得する、ここでは練習htmlファイル URL = "/content/drive/MyDrive/data_science/ren1_html.html" bsoup = BeautifulSoup(open(URL), "html.parser") # BeautifulSoupにページ内容を読み込ませる print("soup:",bsoup.prettify()) #1行に1タグとして整形 news_list = bsoup.find_all("p") #<p>属性を取得する for news in news_list: #news_list表示 print("news_list:" ,news) print(" ") for i in range(0,5+1): #news_listのテキスト部分を表示 print("news_list[%d]:" % (i),news_list[i].text) print(" ") news="" for i in range(0,2+1): #最初の3つを新着ニュースとして取り出す news=news+" 〇"+news_list[i].text print("新着ニュース:",news) ``` GoogleColaboratoryにアップロードすればすぐに動作を確認できます。実行結果のサンプル付きです。 https://colab.research.google.com/drive/1mnA5FzZYHouhr4oiqPSEf-AWCpAo3k3i?usp=drive_link ## 〇補足 公開している動画と解説用pdfは電波新聞社刊行電子工作マガジンに連載された同題名の内容をGoogle NotebookLMにてまとめています