kd_yuta が 2026年01月31日23時08分18秒 に編集
初版
タイトルの変更
振動・音響信号を活用した 異常検知エッジAIモデルの構築
タグの変更
SPRESENSE
エッジAI
加速度センサー
音響工学
センサー
AI
記事種類の変更
製作品
ライセンスの変更
(MIT) The MIT License
本文の変更
1.概要 生産設備の予兆保全では、停止や品質劣化に至る前の異常兆候を早期に捉えることが重要です。現場ではクラウドに送って重い解析を回す方式も多い一方、通信が不安定な場所や電力制約のある場所では、設備の近くで完結するエッジ処理が有効になります。そこで本記事では、Sony SPRESENSEを用いて、加速度と音響を同時に計測し、FFTに基づく特徴量から軽量な機械学習器で異常を判定する構成をまとめます。 本方式のポイントは次の3点です。 1つ目は、加速度3軸と音響の4チャネルをまとめて扱い、設備の状態変化を多面的に捉えることです。 2つ目は、FFTスペクトルをそのまま使うのではなく、0から500 Hzを50等分したbinへ要約して固定長特徴とし、マイコンでも扱いやすい次元へ落とすことです。 3つ目は、学習後の推論をSPRESENSE上で動かし、常時監視と早期警報に直結させることです。 なお図ではaccZの例を示しますが、判定はaccZだけでなくaccXとaccYとmicも含めた4チャネルを同時に用いています。 2.課題背景 2.1.予兆保全で問題になる点 予兆保全をやりたいという要求は強い一方で、現場導入では次のような壁が出ます。 計測はできてもデータが溜まるだけで、異常兆候の判断が属人的になる。 通信前提の設計だと、ネットワークやクラウド運用コストがボトルネックになる。 高精度にしようとしてモデルや特徴が重くなり、現場の小型デバイスでは運用しづらくなる。 このため、現場で扱いやすい設計として、軽量で説明可能性があり、実装も単純な方法が欲しくなります。 2.2.既存の異常検知ソリューションとの位置づけ 近年は生産設備向けに稼働見える化や異常検知を含む製品やサービスも増えています。たとえばNTCのLOSSOは生産現場の異常検知や予兆保全の活用事例を公開しており、現場課題に対して複数プロダクトを組み合わせた解決の考え方が示されています。こうした既存ソリューションは強力ですが、研究や学習用途では、まずは手元の小型デバイスで原理を把握し、異常兆候がスペクトルにどう現れるかを自分のデータで確かめることが重要です。そこで本記事は、エッジ側で完結する最小構成として、FFT特徴とランダムフォレストを用いた異常検知の作り方に焦点を当てます。 参考 NTC LOSSO 公開ページ https://www.ntc.co.jp/LOSS0/ 閲覧日 2026年1月31日 3.構成 3.1.全体の流れ 本方式は、センシング、前処理、FFT特徴抽出、学習器による判定、結果の保存や通知、という順に処理が流れます。基本的には一定長の時系列フレームを切り出し、周波数領域に変換し、固定長の特徴に要約してから分類します。推論までをマイコン上で行うことで、クラウドやPCが無くても異常を検知できます。 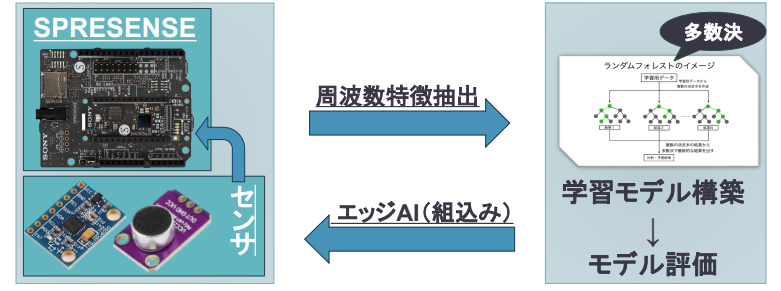 3.2.今回扱うデータの前提 サンプリング周波数は1 kHzです。したがって、解析可能な上限周波数はナイキスト周波数の500 Hzになります。1ファイルは一定長の記録で、加速度3軸と音響の4列を持ちます。データは正常と異常がそれぞれ512ファイルで、合計1024ファイルです。 分割は固定で、正常512のうち学習212、テスト300。異常512のうち学習212、テスト300。合計で学習424、テスト600です。固定分割にすることで再現性を担保します。 4.要素 4.1.ハードウェア 計算基板はSony SPRESENSEです。低消費電力でマルチコアという特徴があり、センサ処理と推論処理を分けるなどの設計が取りやすいです。 https://developer.sony.com/ja/spresense 閲覧日 2026年1月31日 センサは次の組み合わせです。 加速度はMPU6050の3軸を使用します。 音響はMAX4466のアナログマイクアンプを使用します。 加速度だけだと拾いづらい異常が音響に現れることがあり、逆に音響だけだと環境ノイズの影響を受けやすい場面もあるため、両方を同時に扱う狙いがあります。 4.2.前処理とFFT特徴 時系列をそのまま学習器に入れると次元が大きくなりがちなので、周波数領域に変換して要約します。処理の流れは次のとおりです。 1 - 時系列フレームを取り出す 2 - ハニング窓をかける 3 - 片側FFTの振幅スペクトルを得る 4 - 0から500 Hzの範囲を50等分binへ要約する 5 - 4チャネルを連結して200次元特徴にする ハニング窓は、フレーム端の不連続によるスペクトル漏れを抑える目的で用います。窓関数を掛けずに切り出すと、端点で波形が急に切れたように見えてしまい、本来ない周波数成分が広がって見えることがあります。ハニング窓により端点が滑らかになり、ピークや側帯の見え方が安定します。 片側FFTとは、実数信号のFFT結果が正の周波数と負の周波数で対称になる性質を利用して、0からナイキスト周波数までの成分だけを使う方法です。今回はサンプリング周波数が1 kHzなので、0から500 Hzだけ見れば十分です。両側のFFTを扱うよりデータ量が半分になり、マイコン上での計算や特徴生成が軽くなります。 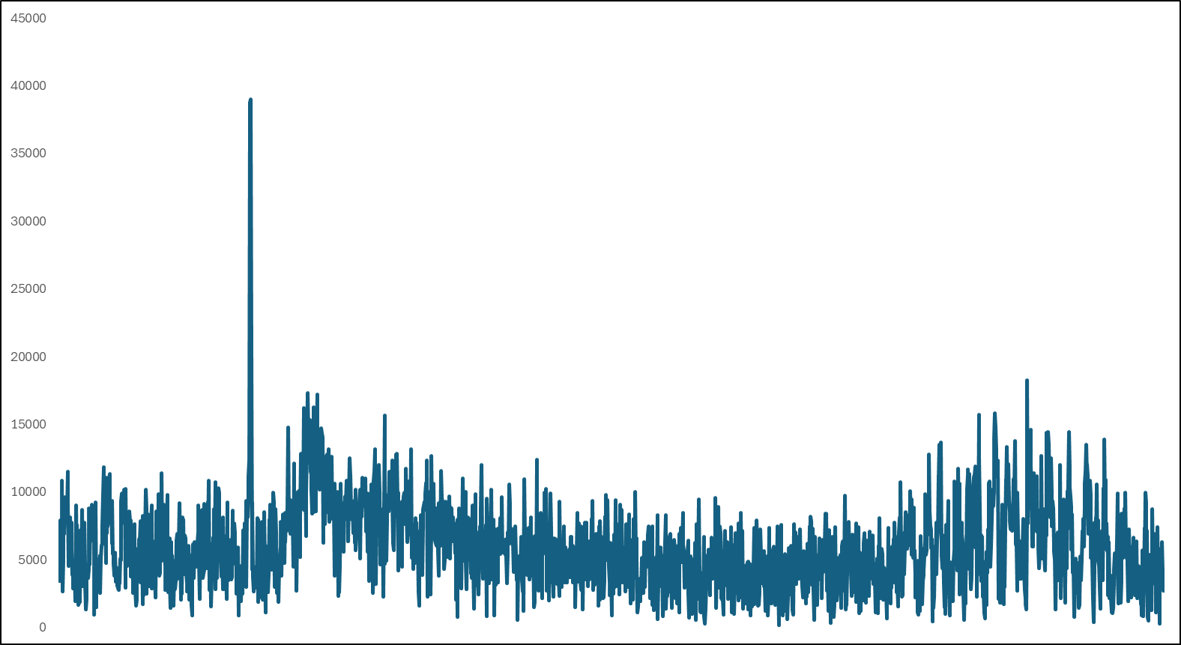 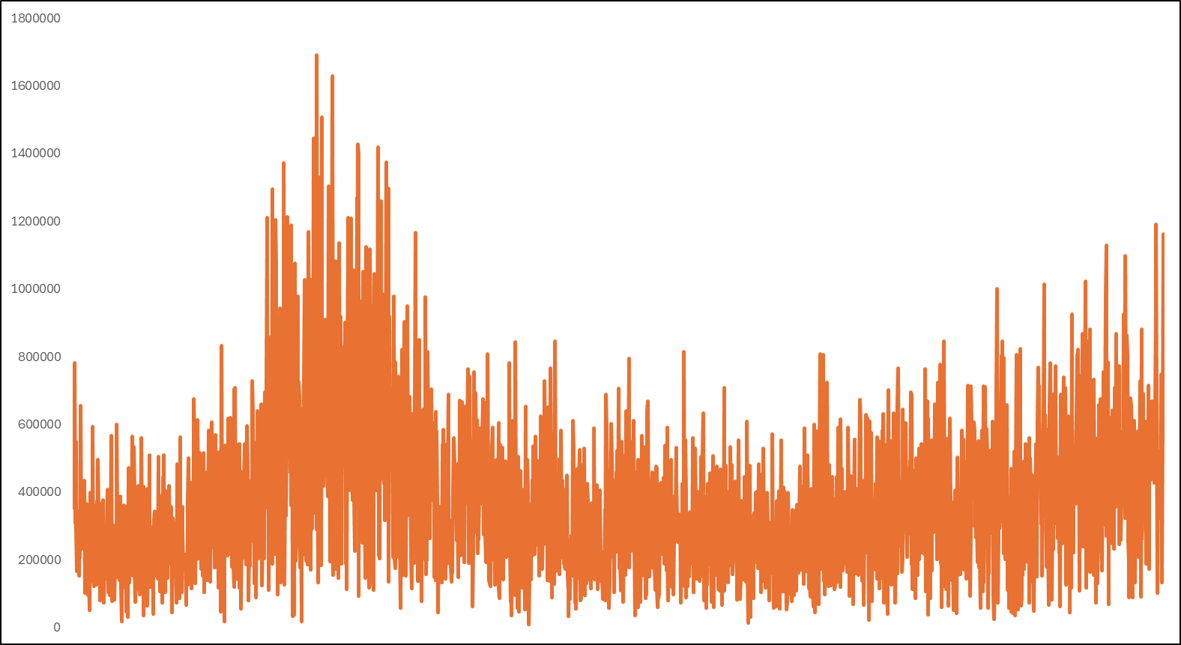 図2と図3はaccZの例ですが、実際の特徴はaccX、accY、accZ、micの4チャネルを同様に処理して連結しています。図は比較が分かりやすいのでaccZだけを提示しています。 4.3.学習器と推論 分類器はランダムフォレストを用います。理由は次のとおりです。 特徴の非線形性に対応できる。 学習後の推論が比較的軽い。 どの特徴が効いたかの見通しが立ちやすい。 学習時は標準化を行い、学習器の入力スケールを揃えます。推論時も同じ標準化パラメータを用いて特徴を変換し、分類します。エッジで動かす場合、学習はPC側で行い、学習済みモデルをSPRESENSEへ移植する形が扱いやすいです。 5.実現のための工夫 5.1.固定長bin化でマイコン実装を簡単にする FFTをそのまま使うと、フレーム長やFFT点数が変わるたびに特徴次元が変化します。そこで0から500 Hzを50等分binに要約し、必ず50次元になる形に揃えます。こうすると、センサ種類を増やしても連結するだけで次元が見積もれ、モデルの入出力が安定します。実装観点では、配列長が固定になり、C言語側への移植もしやすくなります。 5.2.図は白黒前提で作る 学会や技術資料では、モノクロ印刷でも識別できることが重要です。線種や濃淡の差で比較できるようにし、背景は白、線は黒系の濃淡で統一します。今回の図も白黒で出力し、画像はJPEGで保存しています。文字サイズは本文で入れる前提で、図側では最小限にしてあります。 5.3.評価分割を固定して再現性を確保する 試行ごとに学習テスト分割を変えると数値が揺れます。今回は正常512と異常512の合計1024を固定分割し、正常は学習212とテスト300、異常も学習212とテスト300としました。テスト600件を大きめに取ることで、見かけの精度だけが上振れするリスクを下げています。 6.導入検証 6.1.異常時のスペクトル変化 モータに不均衡を誘起した条件では、正常時と比べてスペクトルが広帯域化し、側帯が出る傾向が確認できました。図2と図3はaccZの例です。正常では特定の周波数成分が比較的まとまっているのに対し、異常ではピーク周辺の広がりや付近の成分増加が見えます。こうした変化を50binの要約特徴でも捉えられることが重要です。つまり高精細な解析をしなくても、軽量な特徴で兆候の差を拾える可能性がある、という点がエッジ向きです。 | 状態 | スペクトルの特徴 | |:---:|:---| | 正常 | 特定の周波数成分にエネルギーが集中し、安定している。 | |異常|広帯域化し、ピーク周辺に側帯波が発生。| 6.2.分類性能 テストデータは正常300件と異常300件の合計600件です。分類の結果、正確度は92.0パーセント、異常再現率は100パーセントでした。異常を見逃さないことを重視する用途では、再現率が高いことは重要です。一方で誤警報は運用上の負担にもなるため、今後は閾値設計や二段階判定など、現場運用に合わせた工夫も検討余地があります。 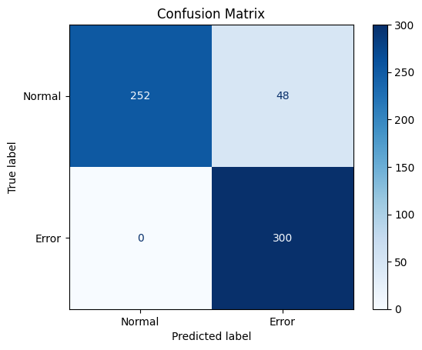 6.3.直感的な分離の確認 特徴空間が本当に分離しているかを直感的に確認するため、PCAで2次元に射影し、SVMで境界を描いた可視化も作成しました。これは最終モデルではなく可視化用ですが、正常と異常が一定のまとまりとして現れ、誤りがどこで起きやすいかの手がかりになります。実運用に向けては、誤りが出る条件を追加計測し、学習データの多様性を増やす方向が有効です。 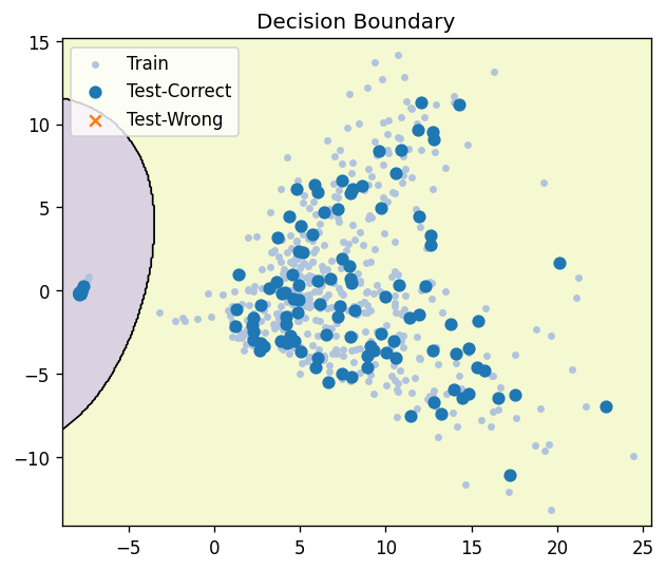 7.終わりに 本記事では、加速度と音響を1 kHzで取得し、片側FFTの振幅スペクトルを50binへ要約し、4チャネルを連結した200次元特徴を用いて、ランダムフォレストで異常検知するエッジ構成をまとめました。図ではaccZの例を示しましたが、実際の判定はaccX、accY、accZ、micの4チャネルを併用しています。テスト600件に対して正確度92.0パーセント、異常再現率100パーセントを得られたことから、FFTに基づく単純な特徴でも兆候の差を捉えられる可能性が示せました。 今後の発展としては次が考えられます。 1 - フレーム長や窓関数の比較により、側帯の見え方と検知性能の関係を詰める 2 - 音響の環境ノイズ対策として、設備固有の周波数帯に重み付けした特徴を作る 3 - 誤警報低減のため、連続判定の多数決や、異常スコアの時系列平滑化を入れる 4 - SPRESENSE上での省電力動作や、異常時のみ保存や通知する運用へ繋げる elchikaでは、同じようにセンサとマイコンで異常検知を試している人も多いと思います。もし、別の窓関数や別の特徴量、またはデータの切り出し方法でより安定した方法があれば教えてください。現場に持ち込める形にするには、解析の精密さ以上に、再現性と運用のしやすさが効いてくると感じています。