takahashisama が 2024年10月30日14時52分34秒 に編集
コメント無し
本文の変更
# 概要
翻訳こんにゃくは、異なる言語を話す人々が瞬時に相互理解を可能にする装置です。このデバイスは、言語の壁を取り払い、コミュニケーションをスムーズに行うために開発されます。今回は装置に話しかけて使用するように作成していきたいと思います。
翻訳こんにゃくは、異なる言語を話す人々が瞬時に相互理解を可能にする装置です。このデバイスは、言語の壁を取り払い、コミュニケーションをスムーズに行うために開発されました。
 # アイデアの詳細
1.音声認識(日本語): マイクから日本語の音声をキャプチャし、Voskライブラリを使用してリアルタイムでテキストに変換します。
1.音声認識(日本語): マイクから日本語の音声をキャプチャし、Voskライブラリ(音声認識)を使用してリアルタイムでテキストに変換します。
2.翻訳(日本語→英語): 認識された日本語のテキストをGoogle翻訳API(googletransライブラリ)を使って英語に翻訳します。 3.音声合成(英語): Google Text-to-Speech(gTTS)ライブラリを使って、翻訳された英語のテキストを音声に変換します。 4.音声ファイルの保存および再生: 生成された音声をMP3形式で保存し、音声再生ツール(mpg123)で再生します 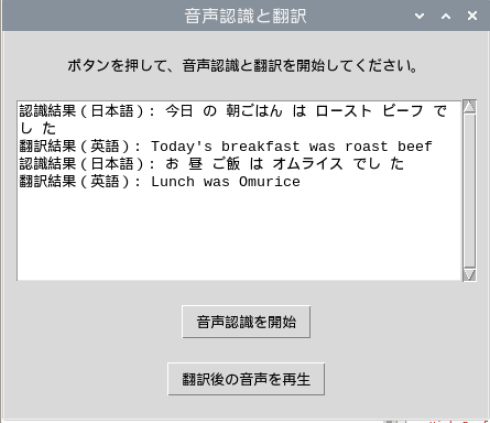 # ソースコード ```arduino: import RPi.GPIO as GPIO import os import queue import sounddevice as sd import vosk import json from googletrans import Translator from gtts import gTTS import tkinter as tk from tkinter import messagebox from tkinter.scrolledtext import ScrolledText LED1 = 17 # LED1のBCM番号の指定 GPIO.setmode(GPIO.BCM) # BCM番号をナンバリングで使用 GPIO.setup(LED1,GPIO.OUT) # LED1のBCM番号を出力に設定 # GUIに必要なモジュール from threading import Thread # Vosk用の日本語モデルのパス model_path = "/home/pi/vosk-model/vosk-model-small-ja-0.22" # Voskのモデルを読み込む if not os.path.exists(model_path): print("モデルが見つかりません。") exit(1) model = vosk.Model(model_path) # サンプリングレートを設定 samplerate = 16000 q = queue.Queue() # 音声入力をキャプチャするためのコールバック関数 def callback(indata, frames, time, status): if status: print(status, file=sys.stderr) q.put(bytes(indata)) # 音声認識、翻訳、音声合成を実行する関数 def recognize(): translator = Translator() with sd.RawInputStream(samplerate=samplerate, blocksize=8000, dtype='int16', channels=1, callback=callback): rec = vosk.KaldiRecognizer(model, samplerate) while True: GPIO.output(LED1,1) # LED1のBCM番号に1を出力(LED点灯) data = q.get() if rec.AcceptWaveform(data): result = rec.Result() result_json = json.loads(result) japanese_text = result_json['text'] print(f"認識結果: {japanese_text}") GPIO.output(LED1,0) # LED1のBCM番号に0を出力(LED消灯) if japanese_text: # 日本語を英語に翻訳 translated_text = translator.translate(japanese_text, src='ja', dest='en').text print(f"翻訳結果: {translated_text}") # 結果をGUIに表示 #result_text.delete(0.0, tk.END) result_text.insert(tk.END, f"認識結果(日本語): {japanese_text}\n") result_text.insert(tk.END, f"翻訳結果(英語): {translated_text}\n") # 英語のテキストを音声に変換し保存 tts = gTTS(text=translated_text, lang='en') tts.save("translated_speech.mp3") messagebox.showinfo("完了", "音声が保存されました。再生ボタンを押して再生できます。") break # 音声認識を別スレッドで実行する def start_recognition(): recognize_thread = Thread(target=recognize) recognize_thread.start() # 音声ファイルを再生する関数 def play_audio(): if os.path.exists("translated_speech.mp3"): os.system("mpg123 translated_speech.mp3") else: messagebox.showwarning("警告", "再生する音声ファイルが見つかりません。") # GUIの設定 root = tk.Tk() root.title("音声認識と翻訳") # メインフレーム frame = tk.Frame(root) frame.pack(padx=10, pady=10) # 説明ラベル label = tk.Label(frame, text="ボタンを押して、音声認識と翻訳を開始してください。") label.pack(pady=10) # テキストエリア(認識結果と翻訳結果の表示用) result_text = ScrolledText(frame, height=10, width=50) result_text.pack(pady=10) # 音声認識ボタン recognize_button = tk.Button(frame, text="音声認識を開始", command=start_recognition) recognize_button.pack(pady=10) # 音声再生ボタン play_button = tk.Button(frame, text="翻訳後の音声を再生", command=play_audio) play_button.pack(pady=10) # GUIのメインループを開始 root.mainloop() ``` # 使用部品 Raspberry Pi 4 USBマイク スピーカー # 参考文献 ・Vosk GitHubリポジトリ: https://github.com/alphacep/vosk-api ・Voskドキュメント: https://alphacephei.com/vosk ・Googletrans GitHubリポジトリ: https://github.com/ssut/py-googletrans ・gTTS GitHubリポジトリ: https://github.com/pndurette/gTTS ・gTTS公式ドキュメント: https://gtts.readthedocs.io/ ・sounddevice公式ドキュメント: https://python-sounddevice.readthedocs.io/ ・mpg123公式サイト: https://www.mpg123.de/