neqo が 2022年09月26日11時49分05秒 に編集
コメント無し
本文の変更
> リサイズした画像がうまく貼れなかったため、画像が見ずらいと思いますが、 「画像をタップするとトリミング前の画像が拡大表示されます。」ということなので、お手数ですが、タップしてみていただけると幸いです。 # 目次 1. はじめに 1. 部品 1. 設計図 1. ソースコード 1. まとめ # はじめに 「[SPRESENSEではじめるローパワーエッジAI](https://www.oreilly.co.jp/books/9784873119670/)」という書籍の中に[DNNRT](https://developer.sony.com/develop/spresense/developer-tools/api-reference/api-references-arduino/classDNNRT.html)ライブラリを使って、**SPRESENSEでAI推論ができる**と記載されていたので、兼ねてから使ってみたいと思っていました!
近年AIといえば、強いGPUで推論する、エッジAIをしたい場合はAI推論専用アクセラレータを利用する。と言ったことが当たり前でした。 しかし、SPRESENSEを使えば、しかも信号処理もできる!
近年AIといえば、強いGPUで推論する・ エッジAIをしたい場合はAI推論専用アクセラレータを利用する。 と言ったことが当たり前でした。 しかし、SPRESENSEを使えば、AI推論ができる! しかも信号処理もできる!
ただ、~~他のマイコンボードと比べると高いんですよね...~~ そんな時、2022年 SPRESENSE™ 活用コンテストを知り、 これだ!と応募してみたところ ・spresense本体 ・拡張ボード をいただきました。 例によるとSPRESENSEでは、 音声コマンド認識(hey, siriとかAlexa!!とかも音声コマンド) ができるようで、 音声コマンド認識を使って、ロボットを呼び応答をしてもらうといった **コミュニケーションボットspr**を作りたくなりました。  こんな感じのを作ろうとしていたのですが、 学位申請や研究発表で多忙で、これを作るのは無理でした。 そこで、音声コマンドとロボットによるモーションにフォーカスして、  こんな感じになりました。 お腹の黒い点は、マイクが音声を取得するための穴です。 実際には、 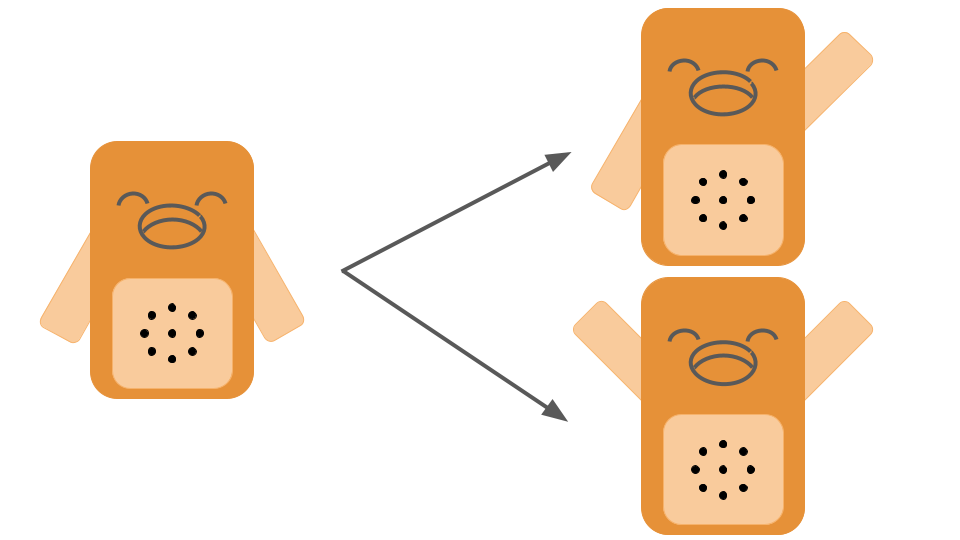 上の図のように、音声コマンドに合わせて、腕をあげたり振ったりということを行います。 (画像では2つのモーションしかありませんが、実は3つ目のモーションがあります。) # 部品 | 部品名 | 個数 | 購入参考URL | |:---|:---|:---| | spresense本体 | 1 | https://www.switch-science.com/products/3900 | | spresense拡張ボード| 1 | https://www.switch-science.com/products/3901 | |サーボモータ| 2 | https://onl.tw/7K5zsh8 | | SD card 32GB | 1 | | | ピンマイク | 1 | BUFFALO BSHSMO3BK など | | 3.5mmステレオミニジャック | 1 | https://akizukidenshi.com/catalog/g/gK-05363/ OR https://www.switch-science.com/products/1170| | ILI9341液晶ディスプレイ|適宜|書籍の再現を忠実に行いたいのであれば必要| |ブレッドボード|適宜|| 特に記載はしませんでしたが、外見を整えるために、
段ボールや両面テープを使っている。
段ボールや両面テープを使っています。
# 設計図 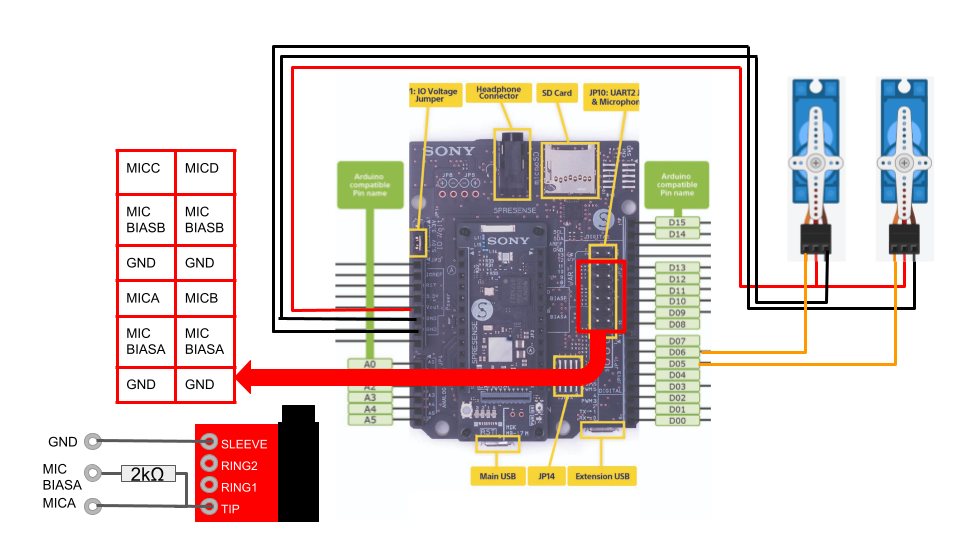 # ソースコード
AI推論のためには、 学習用データとモデルファイル(model.nnb)が必要となりますが、 それらは、書籍の手順に従い、[NNC](https://dl.sony.com/ja/)を利用して作成しました。
``` #ifdef SUBCORE #error "Core selection is wrong!!" #endif #include <Audio.h> #include <FFT.h> #define FFT_LEN 512 // init FFT (Mono, 512 sample) FFTClass<AS_CHANNEL_MONO, FFT_LEN> FFT; AudioClass* theAudio = AudioClass::getInstance(): #include <MP.h> #include <MPMutex.h> // sync subcores MPMutex mutex(MP_MUTEX_ID0); const int subcore = 1; //subcore num struct resultData { float* data; int index; float value; } result; #include <SDHCI.h> SDClass SD; File myFile;; #include <float.h> #include <DNNRT.h> #define NNB_FILE "model.nnb" DNNRT dnnrt; #include <Servo.h> static Servo servo6; // urusai!! static Servo servo5; void setup() { // communicate by serial port Serial.begin(115200); // setting SD card while (!SD.begin()) {Serial.println("insert SD card");} File nnbfile = SD.open(NNB_FILE); if (!nnbfile) { Serial.println(String(NNB_FILE) + " not found"); return; } // begin DNNRT int ret = dnnrt.begin(nnbfile); if (ret < 0) { Serial.println("DNNRT initialization error"); return; } // setting FFT params (hamming window, channel, overlap percentage) FFT.begin(WindowHamming, AS_CHANNEL_MONO, (FFT_LEN/2)); Serial.println("Init audio recorder==============="); theAudio->begin(); theAudio->setRecorderMode(AS_SETRECDR_STS_INPUTDEVICE_MIC); // rec settings: // FORMAT = PCM_16 // DSP_codec_path = /mnt/sd0/BIN // sample_freq 16000Hz, MONO int err = theAudio->initRecorder(AS_CODECTYPE_PCM, "/mnt/sd0/BIN", AS_SAMPLINGRATE_16000, AS_CHANNEL_MONO); if(err != AUDIOLIB_ECODE_OK){ Serial.println("Recorder init error"); while(1); } Serial.println("Start recorder"); theAudio->startRecorder(); MP.begin(subcore); servo6.attach(PIN_D6); servo5.attach(PIN_D5); servo6.write(0); servo5.write(0); } void loop() { static const uint32_t buffering_time = FFT_LEN*1000/AS_SAMPLINGRATE_16000; static const uint32_t buffer_size = FFT_LEN*sizeof(int16_t)*AS_CHANNEL_MONO; static char buff[buffer_size]; // buffer for audio data static float pDst[FFT_LEN]; // buffer for result of mic's FFT uint32_t read_size; int ret; // store in buff ret = theAudio->readFrames(buff, buffer_size, &read_size); if (ret != AUDIOLIB_ECODE_OK && ret != AUDIOLIB_ECODE_INSUFFICIENT_BUFFER_AREA) { Serial.println("Error err = " + String(ret)); theAudio->stopRecorder(); while(1); } // if read_size is not buffer_size if (read_size < buffer_size) { delay(buffering_time); // wait for storing in buff return; } FFT.put((q15_t*)buff, FFT_LEN); // done FFT FFT.get(pDst, 0); averageSmooth(pDst); // buff for histgram of sound level data static const int frames = 32; static float hist[frames]; // buff for spectrogram static const int fft_samples = 96; // 3000Hz static float spc_data[frames*fft_samples]; // shift histgram and spectrogram datas for (int t = 1; t < frames; ++t) { float* sp0 = spc_data+(t-1)*fft_samples; float* sp1 = spc_data+(t )*fft_samples; memcpy(sp0, sp1, fft_samples*sizeof(float)); hist[t-1] = hist[t]; } // total of sound level float sound_power_nc = 0; for (int f = 0; f < FFT_LEN/2; ++f) { sound_power_nc += pDst[f]; } //add last sound level data in histgram hist[frames-1] = sound_power_nc; //add last spectrogram data float* sp_last = spc_data + (frames-1)*fft_samples; memcpy(sp_last, pDst, fft_samples*sizeof(float)); // setting threshould const float sound_th = 40; const float silent_th = 10; float pre_area = 0; float post_area = 0; float target_area = 0; // total soundlevel 250msec、500msec、250msec for (int t = 0; t < frames; ++t){ if (t < frames/4) pre_area += hist[t]; else if (t >= frames/4 && t < frames*3/4) target_area += hist[t]; else if (t >= frames*3/4) post_area += hist[t]; } int index = -1; // recog result for subcore float value = -1; // certainty results for subcore // Quiet threshould at 250ms before and after // loud threshould at 500ms center if (pre_area < silent_th && target_area >= sound_th && post_area < silent_th){ // reset to prevent multiple memset(hist, 0, frames*sizeof(float)); //text for label static const char label[3][8] = {"well", "cute","spr"}; // buff for DNNRT's inputdata DNNVariable input(frames/2*fft_samples/2); // calc MIN, MAX for normalize float spmax = FLT_MIN; float spmin = FLT_MAX; for (int n = 0; n < frames*fft_samples; ++n) { if (spc_data[n] > spmax) spmax = spc_data[n]; if (spc_data[n] < spmin) spmin = spc_data[n]; } //convert (freq)*(times) => (times)*(freq) float* data = input.data(); int bf = fft_samples/2-1; for (int f = 0; f < fft_samples; f += 2) { int bt = 0; // pick up voice for (int t = frames/4; t < frames*3/4; ++t) { // スペクトログラムの最小値・最大値で正規化 float val0 = (spc_data[fft_samples*t+f] - spmin)/(spmax - spmin); float val1 = (spc_data[fft_samples*t+f+1] - spmin)/(spmax - spmin); float val = (val0 + val1)/2; // 平均縮小 val = val < 0. ? 0. : val; val = val > 1. ? 1. : val; data[frames/2*bf+bt] = val; ++bt; } --bf; } // stop recoder for recog theAudio->stopRecorder(); // recog process dnnrt.inputVariable(input, 0); dnnrt.forward(); DNNVariable output = dnnrt.outputVariable(0); // output result ######################################################## index = output.maxIndex(); value = output[index]; if(index == 0){ // "well" raise up spr_bot both hand servo5.write(60); servo6.write(60); delay(1000); servo5.write(0); servo6.write(0); }else(index == 1){ // "cute" be shy (raise up one hand) servo5.write(60); delay(1000); servo5.write(0); }else{ // "spr" call sprbot (wave spr_bot arms) servo5.write(60); servo6.write(60); delay(1000); servo5.write(0); servo6.write(0); delay(1000); servo5.write(60); servo6.write(60); delay(1000); servo5.write(0); servo6.write(0); } //######################################################## theAudio->startRecorder(); //restart recorder } if (mutex.Trylock() != 0) return; //return subcore during int8_t sndid = 100; static const int disp_samples = 96; // sample to subcore static float data[disp_samples]; // data buff to subcore memcpy(data, pDst, disp_samples*sizeof(float)); result.data = data; result.index = index; result.value = value; ret = MP.Send(sndid, &result, subcore); // send data to subcore if (ret < 0) MPLog("FFT data Send Error\n"); mutex.Unlock(); // free MPMutex } void averageSmooth(float* dst) { const int array_size = 4; static float pArray[array_size][FFT_LEN/2]; static int g_counter = 0; if (g_counter == array_size) g_counter = 0; for (int i = 0; i < FFT_LEN/2; ++i) { pArray[g_counter][i] = dst[i]; float sum = 0; for (int j = 0; j < array_size; ++j) { sum += pArray[j][i]; } dst[i] = sum / array_size; } ++g_counter; } ``` # まとめ
色々、今回実現したかったけどできなかったことがたくさんあったし、
色々、今回実現したかったけどできなかったことがたくさんありましたし、
元々作ろうとしていた、ロボットも諦めていないので、 今後も更新を続けていきたいと思います。