chrmlinux03 が 2025年01月28日23時16分39秒 に編集
限定3日公開~♪
本文の変更
## Spresenseマルチコア マンデルブロ集合描画プログラム このプログラムは、Spresenseの秘められた力を解放し、抵抗膜式タッチパネルという古き良きインターフェースを通じて、マンデルブロ集合の神秘に触れることができる、そんな魅惑的なアプリケーションです。 #### 用意するもの | 部品名 | 販売先 | 価格 | 御提供品 | |-|-|-|-| |[SPRESENSEメインボード](https://amzn.to/40xXYeM)|Amazon他|6,080円(税込)|〇| |[SPRESENSE拡張ボード](https://amzn.to/40Aaavz)|Amazon他|4,500円(税込)|〇| |[2.8インチタッチパネル付き液晶](https://amzn.to/4aCAaLn)|Amazon他|1,999円(税込)|〇| |[B-Stem4CM01Display基板](https://www.switch-science.com/products/7996) |スイッチサイエンス|3,300円(税込)|-| | 決して負けない強い力|-|プライスレス|〇| #### タッチパネルを動かす為に B-Stem4CM01Display基板はとっても良い基板なんだけれど タッチパネルまでの配線がされていないのね ここ参照 => [B-Stem4CM01Display にタッチパネルの改造を行うよ](https://elchika.com/article/9fc5216b-1dab-4c65-ad8b-43f5f7943a7e/) に従って改造をします。あ、簡単な半田付けだから大丈夫。 #### タッチパネルの詳細は 抵抗被膜方式やら 静電容量方式に関しては ここ参照 => [LCD液晶基板ili9341でタッチパネルを使うよっ](https://elchika.com/article/eff30d7f-9fac-433e-8863-6dd54206a0fe/) ++**タッチパネル関数や描画関数のライブラリ** spreLgfxTouchをArduino IDEで検索するか [直接これを](https://github.com/chrmlinux/spreLgfxTouch)++ ### マルチコア・マルチスレッドが織りなす高速計算のハーモニー Spresenseの心臓部には、6つのコアが力強く脈打っています。このプログラムでは、その6つのコアを最大限に活用し、マルチコア処理とマルチスレッド処理を融合させることで、マンデルブロ集合の複雑な計算を圧倒的な速度で実行します。 - **Main Core (メインコア)**: - プログラム全体のフローを統括します。 - 画面への描画処理を行い、抵抗膜式タッチパネルからの繊細な入力を感知し、サブコアへのタスク分配を巧みにコントロールします。 :::plantuml:MainCore start :MainCoreの初期化; :SubCore1~5の初期化; repeat :タッチイベント取得; if (領域内ダブルタップ?) then (yes) :拡大処理; elseif (領域外ダブルタップ?) then (yes) :縮小処理; elseif (ドラッグ?) then (yes) :パン処理; endif :描画パラメータ更新; fork :SubCore1でマンデルブロ集合計算; fork again :SubCore2でマンデルブロ集合計算; fork again :SubCore3でマンデルブロ集合計算; fork again :SubCore4でマンデルブロ集合計算; fork again :SubCore5でマンデルブロ集合計算; end fork :描画データ取得; :画面描画; repeat while (プログラム終了?) is (no) stop ::: - **Sub Core (サブコア)**: - メインコアからの指示を受け、マンデルブロ集合の計算という重責を担います。 - 複数のスレッドが並列に動作し、複雑な計算を分担することで、驚異的な処理速度を実現します。 - 計算結果は共有メモリへと書き込まれ、メインコアへと引き継がれます。 :::plantuml:SubCore start :SubCore の初期化; :スレッド作成 x THREADS_PER_CORE; while (プログラム終了?) is (no) fork :スレッド 1 でマンデルブロ集合計算; fork again :スレッド 2 でマンデルブロ集合計算; fork again :スレッド 3 でマンデルブロ集合計算; fork again :スレッド 4 でマンデルブロ集合計算; fork again :スレッド 5 でマンデルブロ集合計算; end fork endwhile stop ::: まるでオーケストラのように、メインコアと5つのサブコア、そして複数のスレッドが協調して動作することで、マンデルブロ集合の神秘を解き明かすための壮大な演奏が始まります。 ### 共有メモリ:コア間を繋ぐ架け橋 :::plantuml:共有メモリ start :描画データ (ピクセルデータ) [320x240]; :ズームレベル; :パン位置 [2]; :スレッドの状態 [30]; :Func() 関数ポインタ; stop ::: マルチコア処理において、コア間でデータを共有することは不可欠です。このプログラムでは、**共有メモリ** という、コア間を繋ぐ架け橋を利用することで、この課題を解決しています。 - **共有メモリ**: - コア間で共有される特別なメモリ領域。 - マンデルブロ集合の計算結果であるピクセルデータはもちろんのこと、ズームレベルやパン位置といった描画パラメータ、さらには各スレッドの状態情報など、様々なデータが格納されます。 各コアは、この共有メモリにアクセスすることで、まるで手紙をやり取りするように、情報を共有することができます。 例えば、メインコアがタッチパネルからの入力情報(ズームやパン)を共有メモリに書き込むと、サブコアはその情報を読み取って、マンデルブロ集合の再計算を行います。そして、計算結果を再び共有メモリに書き込み、メインコアがその情報を読み取って画面を更新する、といった連携プレイを実現しています。 ### ミューテックス:共有メモリへのアクセスの秩序を守る守護者 :::plantuml:mutex(共有メモリ排他制御) start :スレッド N がミューテックスを獲得; if (ミューテックスを獲得できた?) then (yes) :スレッド N が共有メモリにアクセス; :スレッド N が共有メモリからデータを読み書き; :スレッド N がミューテックスを解放; else (no) :スレッド N は待機; endif stop ::: しかし、共有メモリへのアクセスには、注意が必要です。複数のスレッドが同時に共有メモリにアクセスしようとすると、データの不整合が発生し、プログラムが予期せぬ動作をする可能性があります。 そこで、このプログラムでは、**ミューテックス** という、共有メモリへのアクセスの秩序を守る守護者を配置しています。 - **ミューテックス**: - 共有メモリへのアクセスを制御する門番のような存在。 - 複数のスレッドが同時に共有メモリにアクセスしようとすると、ミューテックスがそれを防ぎ、1つのスレッドだけがアクセスできるように制御します。 ミューテックスは、共有メモリへのアクセスを順番待ちさせることで、データの整合性を保ち、プログラムの安定動作を保証します。 共有メモリとミューテックスの巧みな連携により、このプログラムは、コア間通信を安全かつ効率的に行い、Spresenseのマルチコア性能を最大限に引き出しています。 ### 抵抗膜式タッチパネルが誘う、マンデルブロ集合の旅 抵抗膜式タッチパネル。それは、古き良き技術が生み出す、懐かしさと温かさに満ちたインターフェース。このプログラムでは、抵抗膜式タッチパネルの特性を最大限に活かし、マンデルブロ集合をより直感的に、より深く探求できるよう設計しました。 ++**ピンチイン・ピンチアウト** 抵抗被膜式タッチパネル最大の弱点 スマホの様に指でこうぐいって出来ないんですよ でもマンデルブロ集合は作りたひ そこで考え出したのが矩形を画面に常に表示して 枠内枠外をダブルタッチする事によりそれを実現++   - **拡大**: 画面中央に配置された矩形領域。その領域内をダブルタッチすることで、マンデルブロ集合は、まるで宇宙の膨張のように拡大していきます。 - **縮小**: 矩形領域外をダブルタッチすれば、今度は逆に、マンデルブロ集合は収縮し、より広い範囲を俯瞰することができます。 - **パン**: 指先で画面をなぞるようにドラッグすれば、マンデルブロ集合は、まるで生きているかのように滑らかに移動し、隠されたディテールを垣間見ることができます。 抵抗膜式タッチパネルのシンプルな操作性と、マンデルブロ集合の無限の複雑さが織りなすハーモニー。それは、まるで指先で宇宙を操るかのような、未体験の感覚をあなたに提供するでしょう。 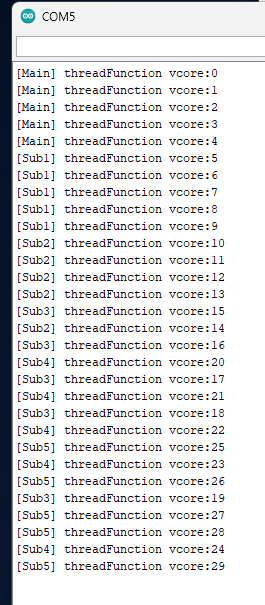 ### シンプルなファイル構成と柔軟な関数呼び出し ```c++:vCore.ino全コード //============================== // vCore.ino // author : chrmlinux03 //============================== #define VIRTUALCORES_USECNT (30) // 1,6,12,30 #include "Common.hpp" #ifdef SUBCORE //------------------------------ // SubCore1..5 (128Kbyte) //------------------------------ #include "SubCore1..5.hpp" #else //------------------------------ // MainCore (640Kbyte) //------------------------------ #include "spreLGFX.hpp" #include "spreTouch.hpp" #include "touchTool.hpp" #include "Func.hpp" //#include "Func2.hpp" #include "MainCore.hpp" #endif ``` ```c++:SubCore1..5.hpp全コード //============================== // SubCore15.hpp // 128Kbyte //============================== int core = SUBCORE; //============================== // setup //============================== void setup(void) { randomSeed(millis()); uint8_t msgid = 0; MP.begin(); MP.Recv(&msgid, &sharedMem); MP.Send(msgid, sharedMem); MP.RecvTimeout(MP_RECV_POLLING); if (THREADS_PER_CORE) { for (int vcore = 0; vcore < THREADS_PER_CORE; vcore++) { pthread_t pt; int* vcorePtr = new int(core * THREADS_PER_CORE + vcore); pthread_create(&pt, NULL, threadFunction, (void *)vcorePtr); } } } //============================== // loop //============================== void loop(void) { yield(); } ``` - **シンプルなファイル構成**: すべてのプログラムファイルを一つのフォルダに集約することで、まるで整理整頓された部屋のように、管理、コンパイル、デプロイが簡単に行えるようになっています。  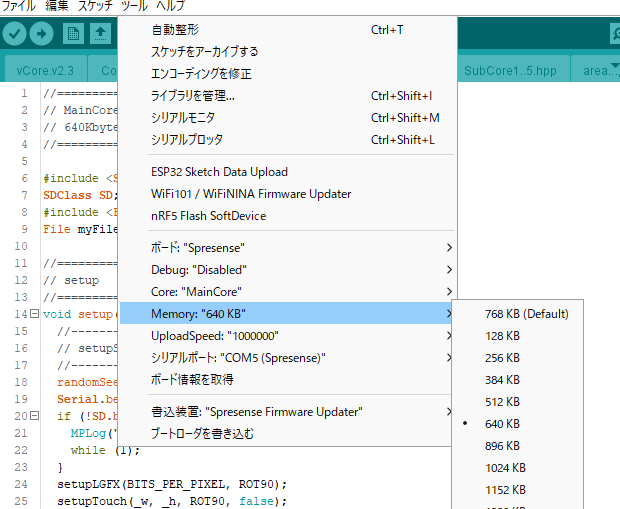 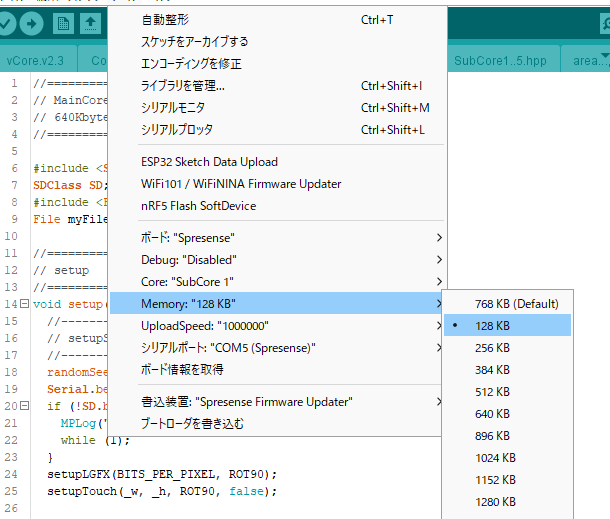 - **Func関数ポインタ**: 共有メモリに Func 関数ポインタを配置することで、メインコア/サブコアから関数を呼び出すための柔軟な仕組みを提供しています。これは、まるでプログラムの各部分が自由に会話できる共通言語のように、様々な処理を動的に実行することを可能にします。 ```c++:MainCore.hpp初期化部分 //----------------------------- // setup sharedMem //----------------------------- memset(sharedMem, 0x0, sz); sharedMem->sz = sz; sharedMem->func = func; sharedMem->scrn.scrnBytes = sizeof(sharedMem->scrn.scrn); sharedMem->scrn.bytesPerVcore = sharedMem->scrn.scrnBytes / VIRTUALCORES_USECNT; sharedMem->scrn.heightPerVcore = SCRN_HEIGHT / VIRTUALCORES_USECNT; sharedMem->scrn.offx = -2.0; sharedMem->scrn.offy = -1.0; sharedMem->scrn.zoom = 0.5; ``` 例えば、`Func.hpp` を差し替えるだけで、マンデルブロ集合の描画アルゴリズムを以下のように変更することができます。 - 単純な白黒の描画から、カラフルなグラデーションを使った描画へ - マンデルブロ集合の計算回数に応じた色分け - 距離推定法を用いた滑らかな陰影付け - 等高線のような表現 また、マンデルブロ集合以外のフラクタル図形 (ジュリア集合など) の描画も、`Func.hpp` を差し替えるだけで実現できます。 このように、`Func` 関数ポインタは、プログラムの拡張性を飛躍的に高める強力なツールです。 **さらに、`Func` 関数ポインタは共有メモリに存在するため、`Func.hpp` の内容を書き換える必要があるのは、Main Coreのみで、Sub Core 1..5 は書き換える必要がありません。** ### 仮想コアとpthread このプログラムでは、Spresenseの6つの物理コアに加えて、**仮想コア** という概念を導入しています。仮想コアとは、1つの物理コア上で複数のスレッドを動作させることで、あたかも複数のコアがあるかのように振る舞わせる技術です。 仮想コアの数は、`vCore.ino` の冒頭で定義されている `VIRTUALCORES_USECNT` というマクロで設定できます。 ```C++ vCore.ino #define VIRTUALCORES_USECNT (30) // 1, 16, 12, 30 のいずれかの値を設定可能 ``` この値を変更することで、1から30までの仮想コアを使用することができます。仮想コア数を増やすことで、より多くのスレッドを並列に実行することができ、マンデルブロ集合の計算をさらに高速化することができます。 **各コアで実行されるpthreadの数は、以下の式で計算されます。** ``` pthreadの数 = VIRTUALCORES_USECNT / REALCORES_MAXCNT ``` ここで、`REALCORES_MAXCNT` はSpresenseの物理コア数であり、6です。 したがって、`VIRTUALCORES_USECNT` が30の場合は、各コアで5つのpthreadが実行されます。 ### データ型と画面サイズ プログラム中で使用される主要なデータ型と画面サイズは、以下のマクロで定義されています。 ```C++ #define FLOAT_T float // 浮動小数点型 float/double #define PIXEL_T uint8_t // 画素のデータ型 #define SCRN_WIDTH (320) // 画面の幅 #define SCRN_HEIGHT (240) // 画面の高さ ``` - `FLOAT_T`: マンデルブロ集合の計算に使用する浮動小数点型です。 `double` 型を使用することで、`float` 型に比べて計算精度が向上し、より正確なマンデルブロ集合を描画することができます。 - `PIXEL_T`: 画面の各画素を表すデータ型です。 `uint8_t` 型を使用することで、1画素あたり8ビット (256階調) のグレースケールでマンデルブロ集合を表示することができます。 :::plantuml:マンデルブロ集合計算 start :ピクセルの座標を取得; :複素数 c を計算; :z = 0; :iteration = 0; repeat :z = z^2 + c; :iteration++; repeat while (|z| < 2 AND iteration < maxIterations); if (iteration == maxIterations) then (yes) :ピクセルを黒で塗る; else (no) :ピクセルを色分けする; endif stop ::: ## さあ、無限の宇宙へ漕ぎ出そう 未知の世界への扉を開き、煌めく星々の海を、あなたと旅したい。 このプログラムが、あなたの好奇心を刺激し、探求心を満たす、かけがえのない羅針盤となるように。 ## コード(ライブラリ以外を掲載) ```c++:Common.hpp //============================== // Common.hpp //============================== #ifndef __COMMON_HPP__ #define __COMMON_HPP__ #include <MP.h> #include <MPMutex.h> MPMutex mtx(MP_MUTEX_ID0); #define MTXENABLE //------------------------------ // define //------------------------------ #define REALCORES_MAXCNT (6) #define THREADS_MAXCNT (6) #define VIRTUALCORES_MAXCNT (THREADS_MAXCNT * REALCORES_MAXCNT) #define THREADS_PER_CORE (VIRTUALCORES_USECNT / REALCORES_MAXCNT) #define FLOAT_T float #define PIXEL_T uint8_t #define BITS_PER_BYTE (sizeof(uint8_t) * 8) #define BYTES_PER_PIXEL (sizeof(PIXEL_T)) #define BITS_PER_PIXEL (BYTES_PER_PIXEL * BITS_PER_BYTE) #define SCRN_WIDTH (320) #define SCRN_HEIGHT (240) #define SCRN_DIM (SCRN_WIDTH * SCRN_HEIGHT) enum {ST_READY, ST_BUSY, ST_FIN, ST_CNTMAX}; //------------------------------ // struct //------------------------------ typedef struct { uint32_t bytesPerVcore; uint32_t heightPerVcore; uint32_t scrnBytes; FLOAT_T offx; FLOAT_T offy; FLOAT_T zoom; PIXEL_T scrn[SCRN_DIM]; } SCRN_T; typedef struct { uint32_t sz; uint8_t stat[VIRTUALCORES_MAXCNT]; SCRN_T scrn; void (*func)(int); } SHARED_MEM_T; SHARED_MEM_T *sharedMem; //------------------------------ // mutex //------------------------------ #ifdef MTXENABLE void mtxLock(void) { int rtn = 0; do { rtn = mtx.Trylock(); } while (rtn != 0); } void mtxUnLock(void) { mtx.Unlock(); } #else void mtxLock(void) {} void mtxUnLock(void) {} #endif //------------------------------ // updStat //------------------------------ void updStat(int vcore, int stat) { mtxLock(); sharedMem->stat[vcore] = stat; mtxUnLock(); } //------------------------------ // isStat //------------------------------ uint8_t isStat(int vcore) { return sharedMem->stat[vcore]; } //------------------------------ // threadFunction //------------------------------ void* threadFunction(void* arg) { int* vcorePtr = (int*)arg; int vcore = *vcorePtr; MPLog("threadFunction vcore:%d\n", vcore); while (1) { if (isStat(vcore) == ST_READY) { updStat(vcore, ST_BUSY); sharedMem->func(vcore); updStat(vcore, ST_FIN); } usleep(100);// yield(); } delete vcorePtr; return NULL; } #endif // __COMMON_HPP__ ``` ```c++:MainCore.hpp //============================== // MainCore.hpp // 640Kbyte //============================== #include <SDHCI.h> SDClass SD; #include <File.h> File myFile; //============================== // setup //============================== void setup(void) { //----------------------------- // setupSystem //----------------------------- randomSeed(millis()); Serial.begin(115200); if (!SD.begin()) { MPLog("ERROR: SD card"); while (1); } setupLGFX(BITS_PER_PIXEL, ROT90); setupTouch(_w, _h, ROT90, false); //----------------------------- // malloc //----------------------------- uint8_t msgid = 10; uint32_t sz = sizeof(SHARED_MEM_T); sharedMem = (SHARED_MEM_T *)MP.AllocSharedMemory(sz); if (!sharedMem) { MPLog("Error: out of memory %d\n", sz); while (1); } //----------------------------- // setup sharedMem //----------------------------- memset(sharedMem, 0x0, sz); sharedMem->sz = sz; sharedMem->func = func; sharedMem->scrn.scrnBytes = sizeof(sharedMem->scrn.scrn); sharedMem->scrn.bytesPerVcore = sharedMem->scrn.scrnBytes / VIRTUALCORES_USECNT; sharedMem->scrn.heightPerVcore = SCRN_HEIGHT / VIRTUALCORES_USECNT; sharedMem->scrn.offx = -2.0; sharedMem->scrn.offy = -1.0; sharedMem->scrn.zoom = 0.5; //----------------------------- // bootup vcore //----------------------------- MP.RecvTimeout(MP_RECV_POLLING); if (THREADS_PER_CORE) { for (int vcore = 0; vcore < VIRTUALCORES_USECNT; vcore++) { static bool subcoreStarted[REALCORES_MAXCNT] = {false}; if (vcore < THREADS_PER_CORE) { pthread_t pt; int* vcorePtr = new int(vcore); pthread_create(&pt, NULL, threadFunction, (void *)vcorePtr); } else { int core = (vcore / THREADS_PER_CORE); if (!subcoreStarted[core]) { MP.begin(core); subcoreStarted[core] = true; } void *dmy; MP.Send(msgid, sharedMem, core); MP.Recv(&msgid, &dmy, core); } } } } //============================== // isRedraw //============================== bool isRedraw(void) { bool rtn = false; int finCnt = 0; for (int vcore = 0; vcore < VIRTUALCORES_USECNT; vcore++) { if (isStat(vcore) == ST_FIN) finCnt++; } if (finCnt == VIRTUALCORES_USECNT) rtn = true; return rtn; } //============================== // drawStats //============================== typedef struct { uint16_t fcol; uint16_t bcol; } TCOL_T; static const TCOL_T tcol[ST_CNTMAX] { {TFT_WHITE, TFT_BLUE}, {TFT_WHITE, TFT_RED}, {TFT_WHITE, TFT_BLUE} // TFT_WHITE, TFT_RED, TFT_BLUE, TFT_GREEN }; void drawStats(LGFX_Sprite * dst, int x, int y) { int stat = 0, gx, gy; int w = 8, h = 4; gx = x; gy = y; for (int vcore = 0; vcore < VIRTUALCORES_USECNT; vcore++) { stat = isStat(vcore); dst->fillRect(gx, gy, w, h, tcol[stat].bcol); gx += 8; } } //============================== // drawScrn //============================== void drawScrn(LGFX_Sprite * dst) { if (isRedraw()) { dst->pushImage(0, 0, _w, _h, sharedMem->scrn.scrn); for (int vcore = 0; vcore < VIRTUALCORES_USECNT; vcore++) { updStat(vcore, ST_READY); } } touchCtrl(dst); drawAst(dst, 0, _h - 8, TFT_BLACK, TFT_WHITE); drawStats(dst, 64, _h - 8); dst->pushSprite(&lcd, 0, 0); } //============================== // mainCoreFunction //============================== void mainCoreFunction(void) { int vcore = 0; if (isStat(vcore) == ST_READY) { updStat(vcore, ST_BUSY); sharedMem->func(vcore); updStat(vcore, ST_FIN); } } //============================== // loop //============================== void loop(void) { if (!THREADS_PER_CORE) { mainCoreFunction(); } drawScrn(&spr); } ``` ```c++:TouchTool.hpp #ifndef __TOUCH_TOOL_HPP__ #define __TOUCH_TOOL_HPP__ //============================== // isInCornerArea //============================== bool isInCornerArea(int tx, int ty) { int x1 = (_w - _hw) / 2; int y1 = (_h - _hh) / 2; int x2 = x1 + _hw; int y2 = y1 + _hh; return (tx >= x1 && tx <= x2 && ty >= y1 && ty <= y2); } void updZoom(int tx, int ty) { const FLOAT_T ZOOM_FACTOR = 2.0f; FLOAT_T offs = 1.0f; mtxLock(); // MPLog("ofx:%.2f ofy:%.2f zm:%.2f\n", sharedMem->scrn.offx, sharedMem->scrn.offy, sharedMem->scrn.zoom); if (isInCornerArea(tx, ty)) { // MPLog("Zooming IN\n"); sharedMem->scrn.zoom *= ZOOM_FACTOR; sharedMem->scrn.offx += offs; sharedMem->scrn.offy += offs; } else { // MPLog("Zooming OUT\n"); sharedMem->scrn.zoom /= ZOOM_FACTOR; sharedMem->scrn.offx -= offs; sharedMem->scrn.offy -= offs; } // MPLog("ofx:%.2f ofy:%.2f zm:%.2f\n", sharedMem->scrn.offx, sharedMem->scrn.offy, sharedMem->scrn.zoom); mtxUnLock(); } //============================== // updOffset //============================== void updOffset(int tx, int ty, int startX, int startY) { mtxLock(); sharedMem->scrn.offx -= ((tx - startX) * (sharedMem->scrn.zoom / _w)); sharedMem->scrn.offy -= ((ty - startY) * (sharedMem->scrn.zoom / _h)); // MPLog("ofx:%.2f ofy:%.2f zm:%.2f\n", sharedMem->scrn.offx, sharedMem->scrn.offy, sharedMem->scrn.zoom); mtxUnLock(); } //============================== // touchCtrl //============================== void touchCtrl(LGFX_Sprite *dst) { const uint16_t DRAG_THRESHOLD = 10; const uint16_t DOUBLE_TAP_THRESHOLD = 300; static int16_t startX = 0, startY = 0; static int16_t lastX = 0, lastY = 0; static uint32_t lastTapTime = 0; static bool dragging = false; int tx = 0, ty = 0, tz = 0; if (isTouch(&tx, &ty, &tz)) { unsigned long currentTime = millis(); if (!dragging) { if (abs(tx - lastX) < DRAG_THRESHOLD && abs(ty - lastY) < DRAG_THRESHOLD) { if (currentTime - lastTapTime < DOUBLE_TAP_THRESHOLD) { //------------------------------ // doubleTap //------------------------------ updZoom(tx, ty); return; } } else { lastTapTime = 0; } lastTapTime = currentTime; startX = tx; startY = ty; dragging = true; } else { //------------------------------ // dragging //------------------------------ updOffset(tx, ty, startX, startY); } lastX = tx; lastY = ty; } else { if (dragging) { dragging = false; } } drawCorner(dst, (_w - _hw) / 2, (_h - _hh) / 2, _hw, _hh, TFT_GREEN); } #endif // __TOUCH_TOOL_HPP__ ``` ```c++:Func.hpp //============================== // Func.hpp //============================== /* void func(int vcore) { sharedMem->scrn.scrn[vcore] = (sharedMem->scrn.scrn[vcore] + 1) % 0xff; return NULL; } */ //============================= // Function1.hpp // Mandelbrot Visualization //============================= // Mandelbrot parameters static const int maxIterations = 64; //============================= // mandelbrot // Calculate if the point belongs to the Mandelbrot set //============================= static int mandelbrot(FLOAT_T real, FLOAT_T imag) { FLOAT_T zr = real; FLOAT_T zi = imag; int iteration = 0; while (zr * zr + zi * zi < 4.0f && iteration < maxIterations) { FLOAT_T temp = zr * zr - zi * zi + real; zi = 2.0f * zr * zi + imag; zr = temp; iteration++; } return (FLOAT_T)iteration; } //============================= // func //============================= bool isCalc(int vcore) { bool rtn = false; static FLOAT_T offx[VIRTUALCORES_USECNT] = {0.0}; static FLOAT_T offy[VIRTUALCORES_USECNT] = {0.0}; static FLOAT_T zoom[VIRTUALCORES_USECNT] = {0.0}; if ((offx[vcore] != sharedMem->scrn.offx) || (offy[vcore] != sharedMem->scrn.offy) || (zoom[vcore] != sharedMem->scrn.zoom)) { offx[vcore] = sharedMem->scrn.offx; offy[vcore] = sharedMem->scrn.offy; zoom[vcore] = sharedMem->scrn.zoom; rtn = true; } return rtn; } //============================= // func //============================= static void func(int vcore) { if (isCalc(vcore)) { FLOAT_T offx = sharedMem->scrn.offx; FLOAT_T offy = sharedMem->scrn.offy; FLOAT_T zoom = sharedMem->scrn.zoom; FLOAT_T asp = (FLOAT_T)SCRN_WIDTH / SCRN_HEIGHT; uint32_t memPos = vcore * sharedMem->scrn.bytesPerVcore; uint32_t heightStart = vcore * sharedMem->scrn.heightPerVcore; uint32_t heightEnd = heightStart + sharedMem->scrn.heightPerVcore; for (uint32_t y = heightStart; y < heightEnd; y++) { for (uint32_t x = 0; x < SCRN_WIDTH; x++) { FLOAT_T real = offx + (asp * 1.0f / zoom) * ((FLOAT_T)x / SCRN_WIDTH); FLOAT_T imag = offy + (1.0f / zoom) * ((FLOAT_T)y / SCRN_HEIGHT); int iterations = mandelbrot(real, imag); uint8_t color = (iterations == maxIterations) ? 0 : (iterations * 255 / maxIterations); sharedMem->scrn.scrn[memPos] = color; memPos++; } } } } ``` ### 今後の展望 - さらに高度なタッチ操作 (回転、マルチタッチなど) を実装し、より直感的な操作を実現します。 - パフォーマンスの最適化 (アルゴリズムの改善、アセンブリ言語の利用など) を行い、より高速な描画を実現します。 - GUIを導入することで、設定画面やパラメータ調整などをグラフィカルに行えるようにし、操作性を向上させます。 - カラーマップの変更機能を追加し、マンデルブロ集合をより多彩な表現で描画できるようにします。 - 計算結果の保存機能を実装し、生成した美しい画像を保存できるようにします。 このプログラムが、Spresenseのマルチコア処理能力と抵抗膜式タッチパネルの可能性を最大限に引き出し、マンデルブロ集合の魅力をより多くの人に伝えることができるよう、開発を続けていきます。 ### さいごに
お疲れさまでございました
お疲れさまでございました。
JAXAさまとかで使ってくれないかしら…。いや、むしろ逆に、JAXAさまが 『このSpresenseアプリ、うちの宇宙ミッションで使いたいんだけど!』 って連絡が来る可能性だってゼロじゃない。そんな日が来るなら、私も宇宙開発の一端を担ったって胸を張れるかもしれないね。