Yakatano が 2026年01月20日01時07分53秒 に編集
初版
タイトルの変更
聴覚Mixed Realityデバイスの作成②:SPRESENSEとマイクアレイで音を見る
タグの変更
SPRESENSE
Microbit
virtualreality
mixedreality
メイン画像の変更
記事種類の変更
製作品
ライセンスの変更
(MIT) The MIT License
本文の変更
# はじめに [聴覚Mixed Realityデバイスの作成①](https://elchika.com/article/b11b7b5e-367c-4690-9fc7-619676d62129/)  前回は「聴覚Mixed Reality(MR)」の構想についてお話ししました。聴覚MRとはどういうものか、そのために必要な技術要素について述べました。 ### やりたいこと 細かいところは[前回](https://elchika.com/article/b11b7b5e-367c-4690-9fc7-619676d62129/)に詳しく説明しているので省きますが,マイクアレイを頭部に搭載し,前方の音を録音します.  マイクのビーム範囲は,頭部に取り付けたカメラのFOV(52.4 deg)に対応させて空間をグリッドに分割します. そうすることで前方の音源の位置と画像の位置を合わせてどこから音がきているか(音源定位),それぞれの音源をバラバラにしてフィルタをかける(音源分離)することが目標になります. 今回は,実際にSONY SPRESENSEとAutolab製のMic&LCD KITを使って、**音の到来方向の可視化(音源定位)と音源分離**するデモを実装していきます。[①](https://elchika.com/article/b11b7b5e-367c-4690-9fc7-619676d62129/)の中から必要な機材のみを使用して機能実装をしていきます. # 機材構成 ### [SPRESENSE](https://developer.spresense.sony-semicon.com/ja#spresense-key-features)  まあ,これがないと始まりませんねw 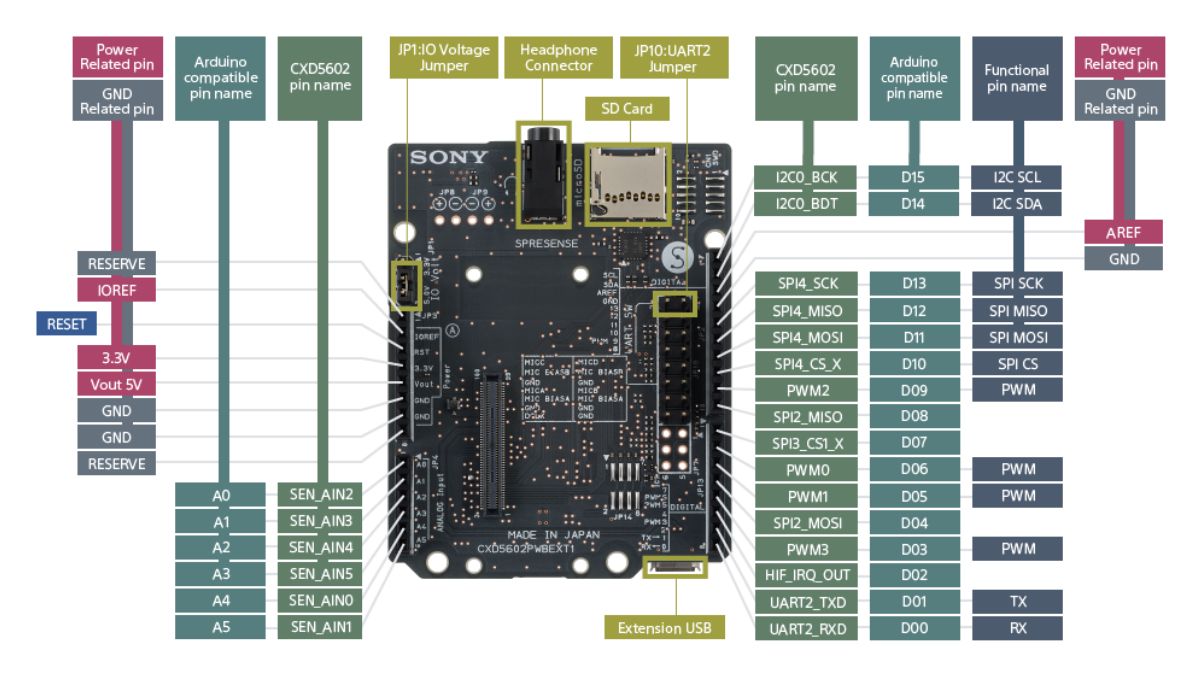 今回は4chアナログ入力が必要なため、LTEボードではなく拡張ボードを使用します。サイズが大きくなるので、ヘッドマウントデバイスとして頭に装着する際の固定方法は一考が必要です(Phase 3で筐体設計予定)。 ### [Mic&LCD KIT for SPRESENSE](https://akizukidenshi.com/catalog/g/g116589/)  ※ 今回はアナログマイクのみでLCDは現時点では使用しません. # ビームフォーミング法 前回も話していますが,ビームフォーミング法にもいくつか手法があります.その中でもリアルタイム性に優れるDelay and Sum(遅延和法)を採用しています. - [ビームフォーミング(遅延和法)の理解](https://qiita.com/TbsYS/items/7c3f09c4ce7bac4af04c) - [ビームフォーミングで特定方向の音源を強調](https://nettyukobo.com/beamformer/) 大雑把にいうと,空間的に配置されたマイクアレイで音源からの音を取ると音源とマイクの距離に応じてそれぞれのマイクに微細な時間遅れ(Delay)が発生します.この遅れは音源の場所ごとに時間遅れのプロファイル(**アレイマニフォールドベクトル(Array Manifold Vector)**)が異なり(右からの音の場合右のマイクには早く,左のマイクには遅れて同じ信号が入ってきます),前方の空間をあらかじめグリッドなどで区切っておくと,グリッドごとに4つのマイクの時間遅れプロファイル(**Array Manifold Vector**)が完成します. 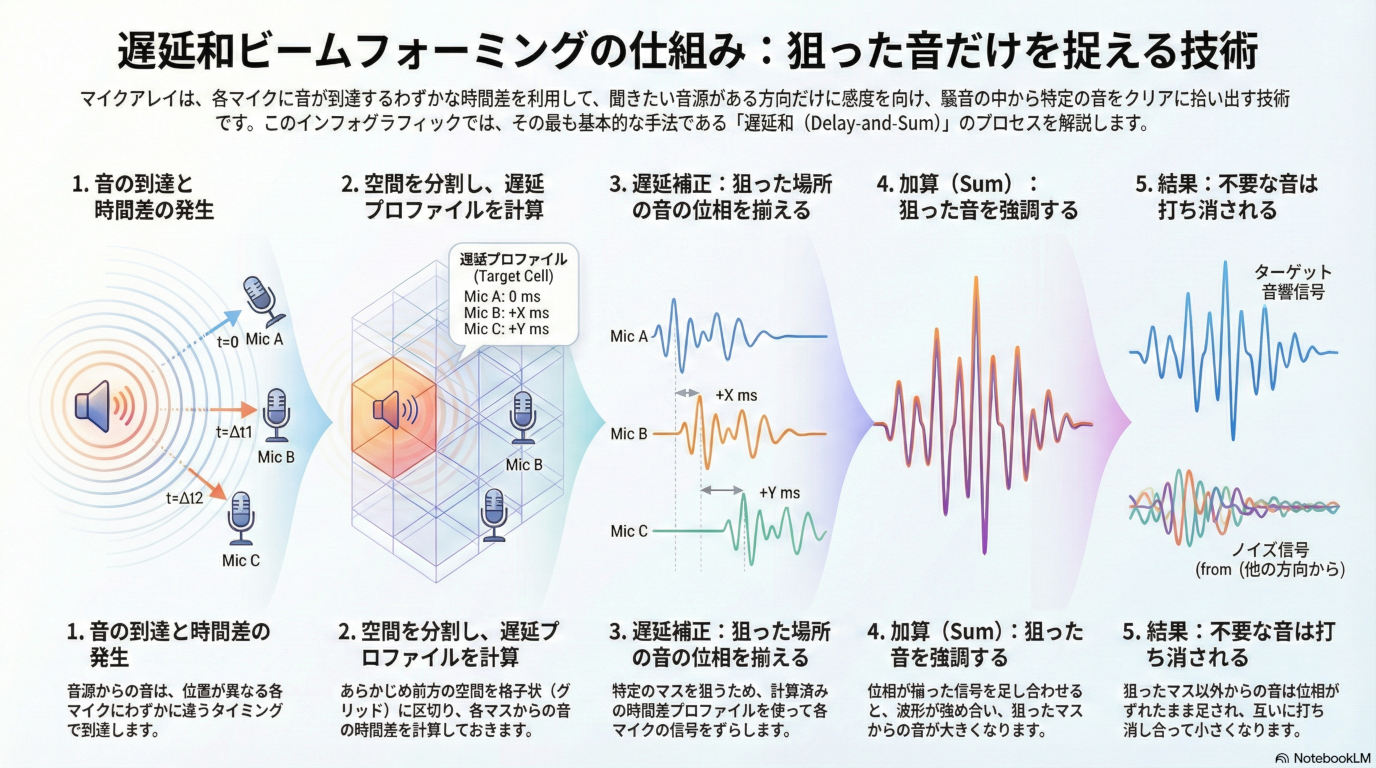 例えば2x1のグリッド位置にある音源を定位したいと考えたとします.この時あらかじめ獲得している2x1グリッドの各マイクの**Array Manifold Vector**を使ってその時間遅れ(Delay)分だけ各マイクの波形をずらして足し合わす(Sum)と,2x1にある音源からの音は時間遅れがきっちり揃って足し合わされるので強めあって大きな音になります.(**遅延和ビームフォーマ(Delay-and-Sum Beamformer: DSBF)**) 対してそれ以外のグリッドにある音源の音は2x1のグリッドの**Array Manifold Vector**を使ってdelayを調整すると完全にずれてしまい,それを足し合わせても互いに弱めあってしまいます. その結果2x1のグリッドの音のみ強めあって音量が大きくなり,それ以外からの音は弱まるためほとんど聞こえなくなる(音量が小さくなる)波形を作ることができます. これを全てのグリッドに対して行うと前方の音場における音源定位ができる,という仕組みです. 次にこれをどれくらいのグリッド数で行うべきかをシミュレーションで検討してみました. ### Delay-and-Sum 解像度検証 **目的**:10x10分割と、バランスを考慮した8x7分割の解像度を比較し、定位能力の差を検証する 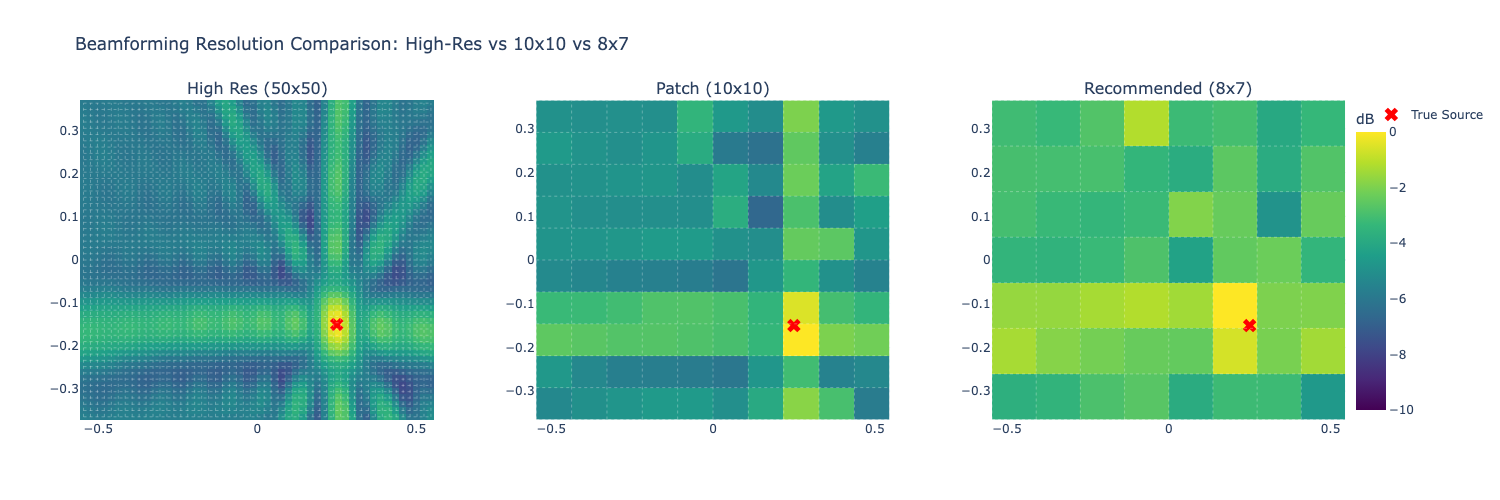 ❌に音源を置き,50x50から8x7までシミュレーションした. **結果**:比較結果より、8x7分割においても音源位置(赤い×印)を含むパッチが正しく最大パワーを示しており、10x10と比較しても定位の明確さに大きな劣化は見られない。これにより、SPRESENSEでのリアルタイム処理に適した効率的な8x7構成の妥当性が確認された その結果8x7でも十分音源を示すことができそうです. ### 8x7グリッド 全56パターン定位検証 **目的**:推奨解像度 8x7 の全領域において、正しくピークが検出されるか網羅的に確認する  **期待**:全てのセルにおいて、赤×印の位置が最大パワー(黄色)を示すこと **結果**:8x7グリッド(計56箇所)の全点検証。解像度を上げたことで、より詳細な空間サンプリングが可能になった。 ### 分解能とリアルタイム性能の解析 **目的**:マイクアレイの物理的な分解能限界と、SPRESENSEでのリアルタイム動作時のFPSを見積もる 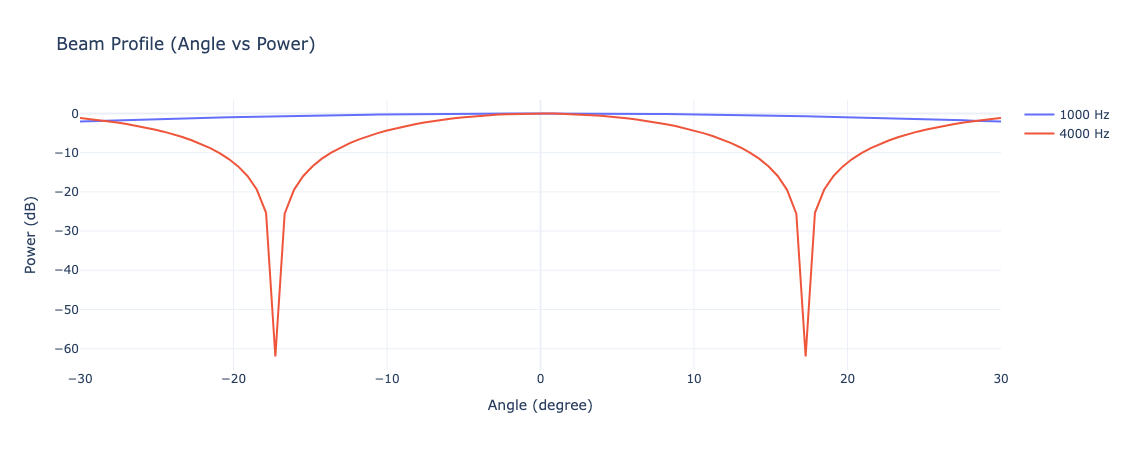 **期待**:マイク間隔が狭いため、低周波での分解能は低く、高周波でも極端に高くはないはず。FPSはパッチ数に反比例する。 **結果**: - ビーム幅 (-3dB): - 1kHz: 60.0度 - 4kHz: 60.0度 - 推奨分割数: FOV 60度に対して、4kHz帯域でもビーム幅は約60.0度あります。 したがって、60 / 60.0 ≒ 1.0 分割程度が物理的な限界です。 余裕を見ても 5x5 ~ 8x8 分割 が妥当であり、10x10はやや過剰スペック(オーバサンプリング)です。 - リアルタイム性能見積もり (SPRESENSE): 10x10パッチ (100点) の場合、周波数領域での最適化計算を行えば、1フレームあたり約 200万命令 (2M ops) 程度の演算量と推定されます。 SPRESENSE (156MHz) の理論値としては 10~15 FPS 程度が限界と予想されます。 5x5パッチ (25点) に減らせば、演算量は1/4になり、40~60 FPS が視野に入ります。 ## アナログマイク接続 アナログマイクを接続して実際に4ch取得できるかチェックしました. 拡張ボードに接続するには[ここの販売元](https://github.com/autolab-fujiwaratakayoshi/MIC-LCD_kit_for_SPRESENSE)を参考にしています. ### マイク配置 アナログマイクを配置するフレームを3Dプリンタで印刷しました(①と同じもの)このマイク座標をconfig.jsonに保存して使用します。  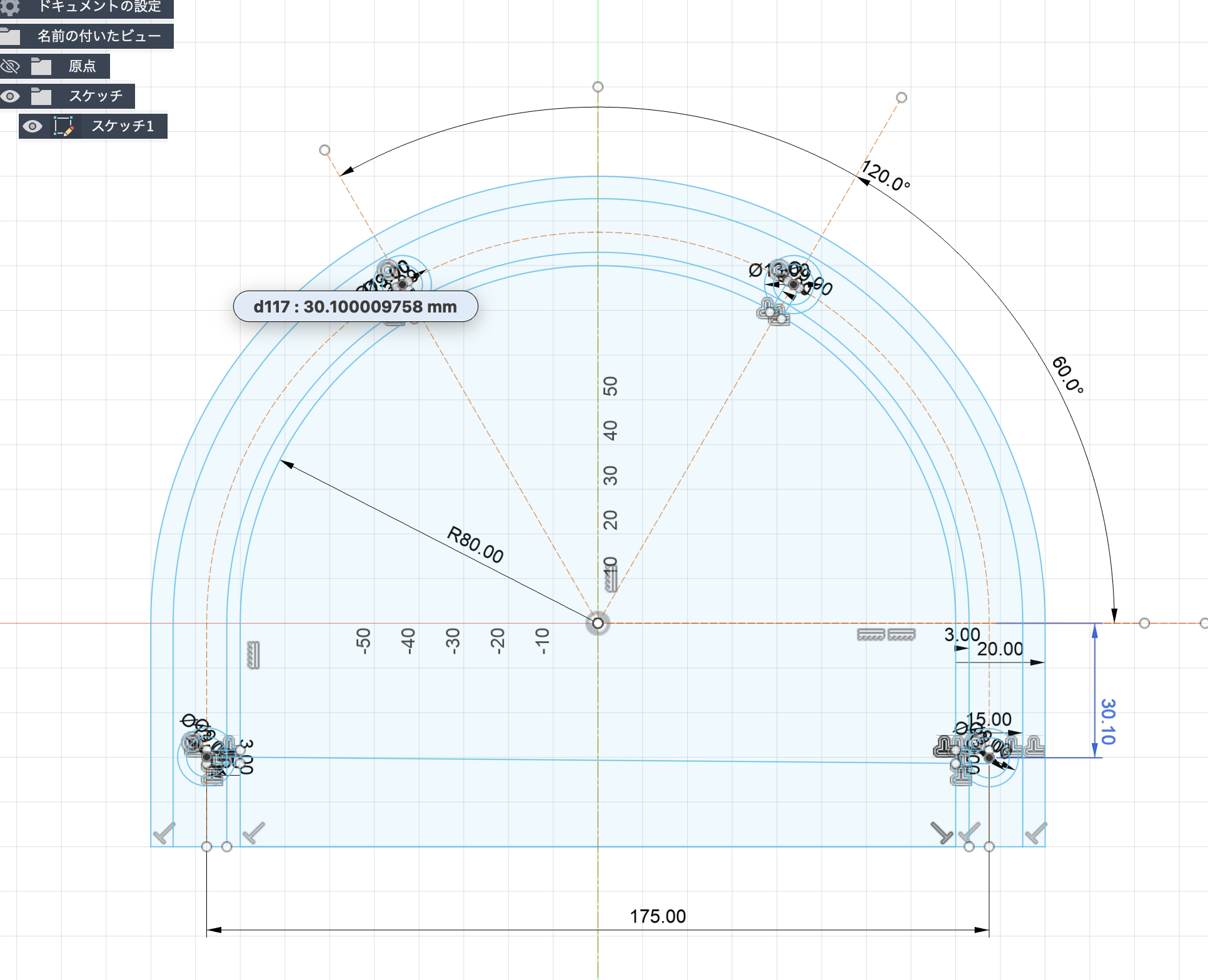 特異点をなくすために配置をわざと不均衡にしたりするアイデアもありますが,まずはこのように均等に配置します. ## キャリブレーションによる定位精度の向上 **目的**:実機測定で得られた補正係数(ゲイン・遅延)を適用することで、定位の焦点がどれだけ改善するかを検証する 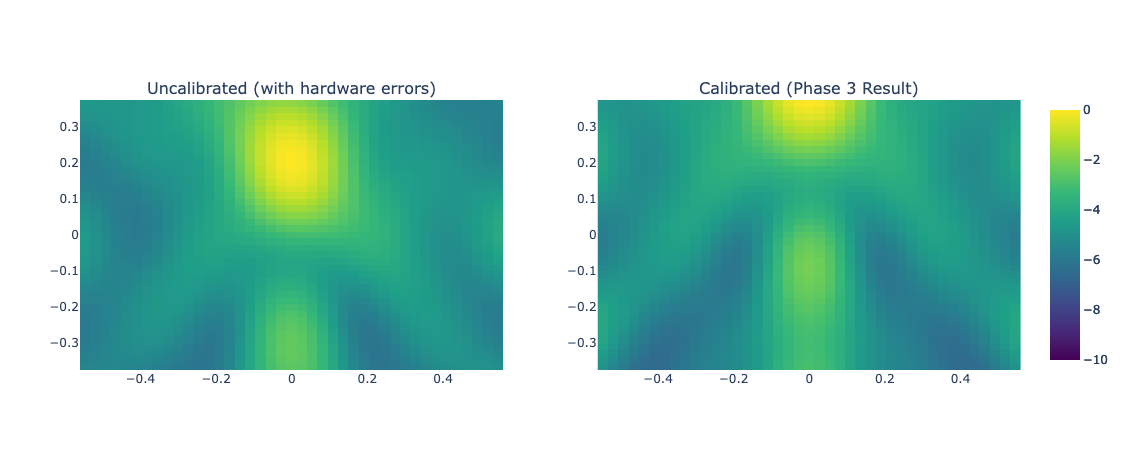 **期待**:補正前はサイドローブが大きくピークがぼやけているが、補正後はピークが鋭くなりダイナミックレンジが改善すること **結果**:比較の結果、補正後は中心のメインローブがより鋭くなり、周辺のノイズ(サイドローブ)が抑えられていることが確認できる。特に遅延補正により位相が揃ったことで、ビームのフォーカス能力が大幅に向上した ### 水平方向の電力分布 **目的**:マイクアレイが **どの方向(水平アングル)から音が来ていると判断しているか**を可視化したものです。 横軸が角度(-90度〜+90度など)、縦軸がパワー(尤度)を表します 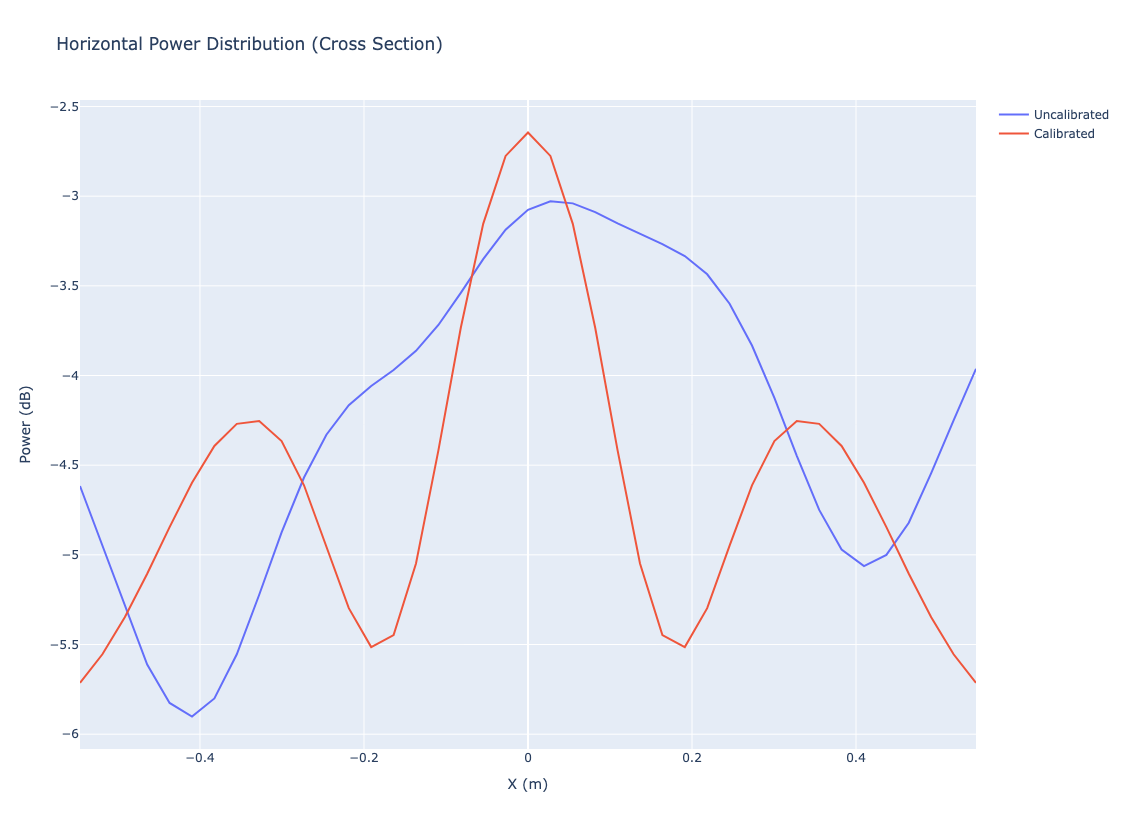 **結果**: - メインローブ(ピーク)の位置:正しさの確認。 評価: 実際の音源方向(例:0度正面)に、最も高いピークが来ているか? - ビーム幅(ピークの鋭さ): 分解能の確認。 評価: 山が鋭いほど高性能(分解能が高い)です。山がブロード(平坦)だと、方向が曖昧になります。 - サイドローブ(脇の小さな山): ノイズ耐性の確認。 評価: メインの山以外に、不要な山(ゴースト)が出ていないか? サイドローブが低いほど優秀です。 ということで,キャリブレーションによって基本性能が高くなったことがわかる. # 実装・評価 本フェーズでは、設計したグリッドの妥当性を詳細シミュレーションで検証するとともに、SPRESENSE上でのリアルタイム動作を想定したC++コアロジックの実装と単体テストを実施しました。また、実際のデバイス形状(ヘッドフォン型、15cm x 10cm)に合わせたパラメータの再定義を行いました。 # 実装 SPRESENSE (Cortex-M4F) 上で、4チャンネルのマイク信号に対してリアルタイムに Delay-and-Sum (DS) ビームフォーミングを行い、音源方向のパワー(または強調音声)を出力するための実装設計です。 ## システムアーキテクチャ リアルタイム処理を実現するため、リングバッファ (Ring Buffer) を用いたストリーム処理を採用します。 ### データフロー概要 - Input (Microphone): 4chのアナログマイク信号をDMA転送で取得。 - Buffering: 取得したデータをリングバッファへ書き込み。 - Processing (Chunk): 一定サイズ(チャンク)ごとにリングバッファからデータを読み出し、遅延・加算処理を実行。 - Output: 計算されたパワーマップ(数値)または強調音声(波形)を出力。 ### リングバッファの必要性 Delay-and-Sum では、マイク間の到達時間差を補正するために、信号を「遅延」させる必要があります。つまり、「過去のサンプル」 にアクセスする必要があります。 リングバッファを使用することで、常に最新の $N$ サンプルと、必要な最大遅延量分の過去データをメモリ上に保持します。 ## 典型的な実装パターンと調査結果 既存の組み込みシステムにおけるビームフォーミング実装事例を調査した結果、本設計は標準的な「リングバッファ + チャンク処理」パターンに合致しています。 ### データ構造:リングバッファ (Ring Buffer) Delay-and-Sum法は「過去の信号」を参照する必要があるため、バッファ管理が設計の肝となります。 * 役割: 各マイクチャンネルごとに用意し、常に最新の $N$ サンプルと、必要な最大遅延量分の過去データを保持します。 * 読み出し: 遅延させたい量(サンプル数)だけ「Head」から遡った位置からデータを読み出します。 * ReadIndex = (HeadIndex - DelaySamples) % BufferSize ```arduino:RingBuffer.h #ifndef RING_BUFFER_H #define RING_BUFFER_H #include <stddef.h> #include <stdint.h> #include <string.h> // for memcpy // A generic Ring Buffer implementation for audio samples (int16_t) // Assuming single channel per buffer instance. class RingBuffer { public: RingBuffer(size_t size); ~RingBuffer(); // Push new data into the buffer // Advances the head pointer. void push(const int16_t* data, size_t length); // Get a delayed chunk of data // delay_samples: How many samples back from the HEAD to start reading. // length: Number of samples to read. // output: Buffer to store the read data. // Returns true if successful, false if requested data exceeds buffer history. bool get_delayed(size_t delay_samples, size_t length, int16_t* output); // Get the current write position index (for debugging) size_t get_head_index() const { return head_; } private: int16_t* buffer_; size_t size_; size_t head_; // Points to the next index to write }; #endif // RING_BUFFER_H ``` ```arduino:RingBuffer.cpp #include "RingBuffer.h" #include <algorithm> // for std::min RingBuffer::RingBuffer(size_t size) : size_(size), head_(0) { buffer_ = new int16_t[size]; // Initialize with zeros memset(buffer_, 0, size * sizeof(int16_t)); } RingBuffer::~RingBuffer() { delete[] buffer_; } void RingBuffer::push(const int16_t* data, size_t length) { if (length > size_) { // Input too large, only take the last 'size_' elements data += (length - size_); length = size_; } size_t space_at_end = size_ - head_; if (length <= space_at_end) { // Fits in one go memcpy(buffer_ + head_, data, length * sizeof(int16_t)); head_ += length; } else { // Wrap around memcpy(buffer_ + head_, data, space_at_end * sizeof(int16_t)); size_t remaining = length - space_at_end; memcpy(buffer_, data + space_at_end, remaining * sizeof(int16_t)); head_ = remaining; } // Normalize head index just in case (though logic above handles it) if (head_ >= size_) { head_ = 0; } } bool RingBuffer::get_delayed(size_t delay_samples, size_t length, int16_t* output) { // Basic check: delay + length shouldn't exceed buffer size if ((delay_samples + length) >= size_) return false; // head_ points to the *next* write position. // The most recent 'length' samples start at (head_ - length). // With 'delay_samples', we go further back: (head_ - length - delay_samples). intptr_t read_idx_signed = (intptr_t)head_ - (intptr_t)length - (intptr_t)delay_samples; while (read_idx_signed < 0) { read_idx_signed += size_; } size_t read_idx = (size_t)read_idx_signed; // Copy logic size_t space_at_end = size_ - read_idx; if (length <= space_at_end) { memcpy(output, buffer_ + read_idx, length * sizeof(int16_t)); } else { memcpy(output, buffer_ + read_idx, space_at_end * sizeof(int16_t)); size_t remaining = length - space_at_end; memcpy(output + space_at_end, buffer_, remaining * sizeof(int16_t)); } return true; } ``` ### 処理単位:ブロック処理 (Chunk Processing) 1サンプルずつの処理はオーバーヘッドが大きいため、チャンク(ブロック)単位(例: 64, 128, 256サンプル)で処理するのが一般的です。SPRESENSEのAudioライブラリもブロック単位でデータを提供するため、これに合わせるのが効率的です。 ### 遅延計算:整数遅延 vs 分数遅延 整数遅延 (Integer Delay): round(遅延秒数 * Fs) で最も近いインデックスを選択。計算が高速で、Cortex-M4Fでのリアルタイム処理に適しています。まずはこれを採用します。 分数遅延 (Fractional Delay): 線形補間等でサンプル間の値を推定。精度は向上しますが計算コストが増加します。将来的な改善項目とします。 ### SPRESENSE特有の事情 SPRESENSEのAudio Libraryは内部でFIFOバッファを持っていますが、ビームフォーミングでは各チャンネルで異なる遅延量のランダムアクセスが必要となるため、自前のリングバッファクラスを用意してデータを再管理する構成が推奨されます。 ### ホワイトノイズ印加実験 **目的**:マイクアレイの左側,右側からそれぞれホワイトノイズを印加した場合の波形をチェック - 左側にホワイトノイズ設置:waveform_1768824050 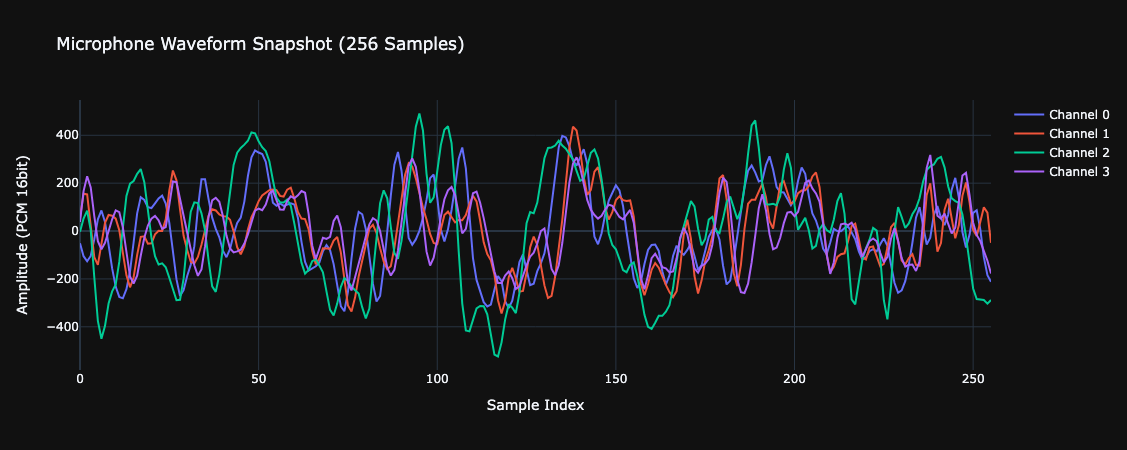 **結果**:左側のマイク(ch1, ch3)の振幅が大きい - 右側にホワイトノイズ設置:waveform_1768824061 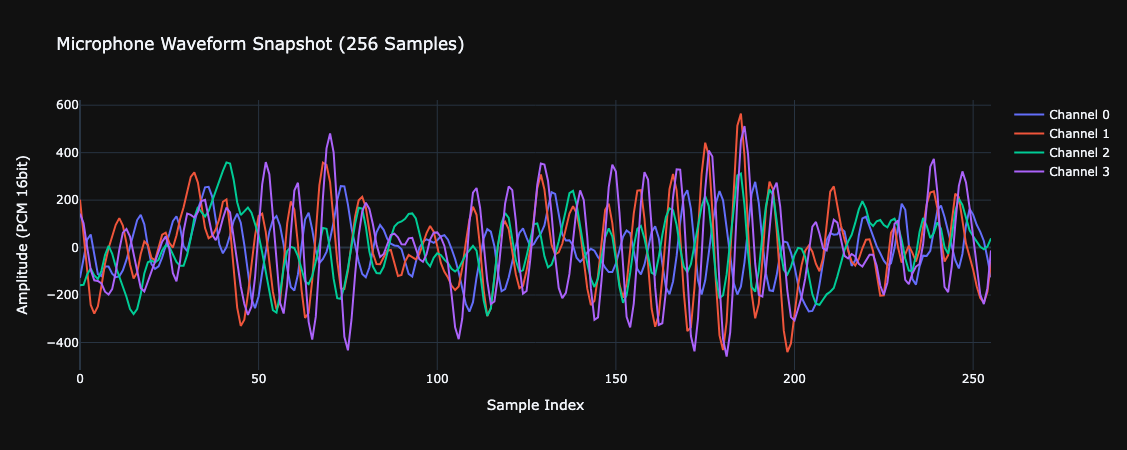 **結果**:ch2,ch4の振幅が大きく,ch1,ch3が小さいため,正常に音を取れていることがわかる. ### 簡単にホワイトノイズを出す方法 [【寝かしつけ】iPhoneのホワイトノイズを最短経路でONにする](https://note.com/tsummm/n/n655aa3772820) ## 空間フィルタリング(Selective Filtering)の設計 ユーザーの最終目標である「ブロックごとに異なるフィルタをかけ、原音に合成する」処理を実現するための設計です。 ### 概念:Spatial Equalizer 単に一つの方向を取り出すだけでなく、空間全体を複数のセクター(パッチ)に分割し、各セクターからの音に個別のゲインや周波数フィルタ(EQ)を適用して再合成するアプローチです。 $$ Output(t) = \sum_{p=0}^{P-1} \text{Filter}_p \left( \text{Beamformer}_p(t) \right) $$ しかし、全パッチ(56個)に対してビームフォーミングとフィルタリングを行うのは計算コスト的に不可能です。 ### 現実的な実装アプローチ:ROI (Region of Interest) 方式 全てのパッチを常時処理するのではなく、「注目領域(ROI)」のみを処理し、それ以外は「背景音(Background)」として扱う、あるいは減衰させる方式を提案します。 **手順** - パワーマップ計算: 全パッチの音響パワーを計算(これは現在の実装で可能)。 - ROI決定: パワーが閾値を超えたパッチ、またはユーザーが指定したパッチを特定。 例: 「右上のブロック」だけ抽出したい。 - 選択的ビームフォーミング: ROIに対応するパッチの遅延パラメータを使って extract_audio を実行。 - フィルタリング: 抽出された音声に対して、Low-pass, High-pass, GainなどのDSP処理を適用。 - ミキシング: 処理後の音声を最終出力バッファに加算。 原音(無指向性成分)とミックスする比率を調整することで、「特定の音だけ強調」や「特定の音だけ消す」を実現。 ``` graph TD subgraph Signal_Processing_Loop MIC[Mic Input] --> RB[Ring Buffer] subgraph Analysis_Phase RB --> SCAN[Power Scan (All Patches)] SCAN --> MAP[Power Map] MAP --> DECIDE[Decide ROI / User Selection] end subgraph Synthesis_Phase DECIDE -->|Target Indices| LOOP[Loop for Targets] LOOP --> BF[Beamforming (Delay-and-Sum)] BF --> AUDIO[Extracted Audio Chunk] AUDIO --> FILTER[Apply Filter / Gain] FILTER --> MIX[Mix to Output] MIX --> LOOP end MIX --> DAC[Audio Output] end ``` ### 処理フローチャート (Updated) このアーキテクチャにより、「特定のブロックからの音源のみ強調(他をミュート)」も、「特定のブロックだけミュート(他はスルー)」も柔軟に実現可能です。 ```arduino:Beamformer.h #ifndef BEAMFORMER_H #define BEAMFORMER_H #include "config.h" #include "RingBuffer.h" #include <vector> class Beamformer { public: Beamformer(); ~Beamformer(); // Initialize: Pre-calculate delay tables for all grid patches void init(); // Process a chunk of multi-channel audio // input_channels: Array of pointers to input buffers (size: CHUNK_SIZE each) // output_powers: Array to store power of each patch (size: PATCH_X * PATCH_Y) void process(const int16_t* const* input_channels, float* output_powers); // Process a chunk to extract audio from a specific patch // target_patch_index: The index of the grid patch to focus on // output_audio: Buffer to store the enhanced audio (size: CHUNK_SIZE) // Note: input_channels data must be pushed via process() or push_inputs() first. // Ideally, process() does pushing, and this function uses the buffered data. // But for flexibility, let's allow pushing separately or reuse buffer state. // Current design: process() pushes. So call process() first to update buffers, then this? // Better: Add a method to just push, and separate calc_power and calc_audio. void push_input(const int16_t* const* input_channels); void calculate_powers(float* output_powers); void extract_audio(int target_patch_index, int16_t* output_audio); // Get the number of patches int get_patch_count() const { return PATCH_X * PATCH_Y; } private: RingBuffer* ring_buffers_[CHANNEL_COUNT]; // Delay table: [patch_index][channel_index] -> delay in samples // Flattened: index = patch_idx * CHANNEL_COUNT + ch std::vector<int> delay_table_; // Calculate grid centers and delays void calculate_look_up_table(); }; #endif // BEAMFORMER_H ``` ```arduino:Beamformer.cpp #include "Beamformer.h" #include <Arduino.h> #include <algorithm> #include <cmath> #include <cstring> Beamformer::Beamformer() { for (int i = 0; i < CHANNEL_COUNT; ++i) { // Buffer size should be CHUNK_SIZE + Max Delay // Max delay for 1m array at 48kHz ~ 140 samples. // 15cm array ~ 21 samples. // BUFFER_SIZE defined in config.h (e.g. 1024) is sufficient. ring_buffers_[i] = new RingBuffer(BUFFER_SIZE); } } Beamformer::~Beamformer() { for (int i = 0; i < CHANNEL_COUNT; ++i) { delete ring_buffers_[i]; } } void Beamformer::init() { calculate_look_up_table(); } void Beamformer::calculate_look_up_table() { int num_patches = PATCH_X * PATCH_Y; delay_table_.resize(num_patches * CHANNEL_COUNT); // Grid generation logic (Should match Python simulation) // Projection plane at Z = FOCAL_DISTANCE float x_max = FOCAL_DISTANCE * tanf(CAMERA_FOV_X / 2.0f); float y_max = FOCAL_DISTANCE * tanf(CAMERA_FOV_Y / 2.0f); float dx = 2.0f * x_max / PATCH_X; float dy = 2.0f * y_max / PATCH_Y; for (int py = 0; py < PATCH_Y; ++py) { for (int px = 0; px < PATCH_X; ++px) { int patch_idx = py * PATCH_X + px; float p_x = -x_max + dx / 2.0f + px * dx; float p_y = -y_max + dy / 2.0f + py * dy; // Full 2D Scan float p_z = FOCAL_DISTANCE; // Calculate distance to each mic float dists[CHANNEL_COUNT]; for (int ch = 0; ch < CHANNEL_COUNT; ++ch) { float mx = MIC_POS[ch].x; float my = MIC_POS[ch].y; float mz = MIC_POS[ch].z; float dist = sqrtf(powf(p_x - mx, 2) + powf(p_y - my, 2) + powf(p_z - mz, 2)); dists[ch] = dist; } float ref_dist = FOCAL_DISTANCE + 0.5f; for (int ch = 0; ch < CHANNEL_COUNT; ++ch) { float time_diff = (ref_dist - dists[ch]) / SOUND_SPEED; int delay_samples = (int)roundf(time_diff * SAMPLE_RATE); int total_delay = delay_samples + MIC_DELAY_CORRECTION[ch]; if (total_delay < 0) total_delay = 0; delay_table_[patch_idx * CHANNEL_COUNT + ch] = total_delay; } } } // Debug: Print Delay Table Stats int min_d = 10000, max_d = -10000; for (size_t i = 0; i < delay_table_.size(); ++i) { if (delay_table_[i] < min_d) min_d = delay_table_[i]; if (delay_table_[i] > max_d) max_d = delay_table_[i]; } Serial.print("Delay Table Range: "); Serial.print(min_d); Serial.print(" to "); Serial.println(max_d); } void Beamformer::push_input(const int16_t *const *input_channels) { for (int ch = 0; ch < CHANNEL_COUNT; ++ch) { ring_buffers_[ch]->push(input_channels[ch], CHUNK_SIZE); } } void Beamformer::calculate_powers(float *output_powers) { int num_patches = PATCH_X * PATCH_Y; std::memset(output_powers, 0, num_patches * sizeof(float)); // --- Full 2D Scan over all patches --- for (int py = 0; py < PATCH_Y; ++py) { for (int px = 0; px < PATCH_X; ++px) { int p = py * PATCH_X + px; // Perform Delay-and-Sum for all channels // For efficiency, accumulators double sum_sq = 0; // Temporary buffer for mixing (or just mix sample by sample) // Ideally: sum(sig_ch[t]) for t in chunk // To minimize memory, let's iterate sample first? // - Calling get_delayed k times per sample is slow. // - Calling get_delayed k times per patch is better. // Strategy: Get aligned buffers for all channels int16_t *aligned_signals[CHANNEL_COUNT]; // We need storage for them. Since CHUNK_SIZE is small (256), stack alloc // ok? 4 * 256 * 2bytes = 2KB. SPRESENSE stack is usually large enough. int16_t sig_bufs[CHANNEL_COUNT][CHUNK_SIZE]; bool data_ok = true; for (int ch = 0; ch < CHANNEL_COUNT; ++ch) { int delay = delay_table_[p * CHANNEL_COUNT + ch]; if (!ring_buffers_[ch]->get_delayed(delay, CHUNK_SIZE, sig_bufs[ch])) { data_ok = false; break; } aligned_signals[ch] = sig_bufs[ch]; } if (!data_ok) continue; // Calculate Power (Mean Square of Sum) for (int i = 0; i < CHUNK_SIZE; ++i) { float mixed = 0.0f; for (int ch = 0; ch < CHANNEL_COUNT; ++ch) { mixed += (float)aligned_signals[ch][i]; } sum_sq += (double)(mixed * mixed); } output_powers[p] = (float)(sum_sq / CHUNK_SIZE); } } } void Beamformer::extract_audio(int target_patch_index, int16_t *output_audio) { if (target_patch_index < 0 || target_patch_index >= (PATCH_X * PATCH_Y)) { std::memset(output_audio, 0, CHUNK_SIZE * sizeof(int16_t)); return; } int16_t delayed_signal[CHUNK_SIZE]; float summed_signal[CHUNK_SIZE]; std::memset(summed_signal, 0, sizeof(summed_signal)); // Sum for (int ch = 0; ch < CHANNEL_COUNT; ++ch) { int delay = delay_table_[target_patch_index * CHANNEL_COUNT + ch]; if (ring_buffers_[ch]->get_delayed(delay, CHUNK_SIZE, delayed_signal)) { float gain = MIC_GAIN_CORRECTION[ch]; for (int i = 0; i < CHUNK_SIZE; ++i) { summed_signal[i] += (float)delayed_signal[i] * gain; } } } // Normalize and Convert to int16 // Simple average sum: output = sum / CHANNEL_COUNT float scale = 1.0f / CHANNEL_COUNT; for (int i = 0; i < CHUNK_SIZE; ++i) { float val = summed_signal[i] * scale; // Clip if (val > 32767.0f) val = 32767.0f; if (val < -32768.0f) val = -32768.0f; output_audio[i] = (int16_t)val; } } void Beamformer::process(const int16_t *const *input_channels, float *output_powers) { push_input(input_channels); calculate_powers(output_powers); } ``` ## ビームフォーミング結果 印加したホワイトノイズを使ってビームフォーミングで音源定位を行った. (実験の簡略化のため,グリッドを6x5に減らして実験) - waveform_1768824050 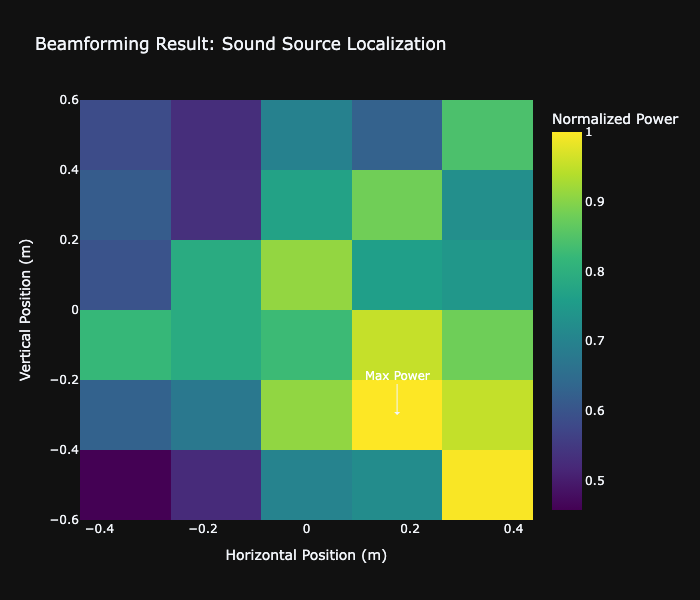 - waveform_1768824061 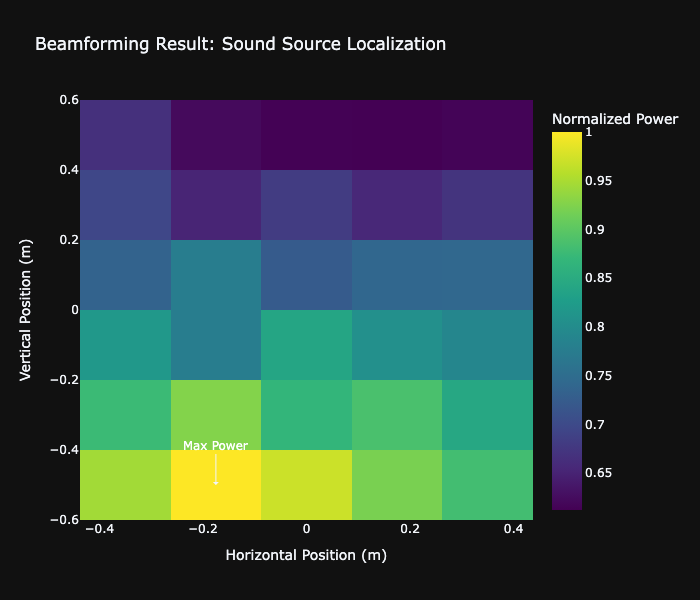 音源推定が左右でできていることがわかります. ## 結果 現在の設定 (config.h) では以下の通りです。 - サンプリングレート: 16,000 Hz (16kHz) - チャンクサイズ: 256 サンプル したがって、1チャンクあたりの時間は: $$ \frac{256 \text{ samples}}{16000 \text{ Hz}} = 0.016 \text{ sec} = \mathbf{16 \text{ ms}} $$ となります。 ビームフォーミングはこの時間間隔で処理されているため,リアルタイムでの処理が可能です(6x5の場合) ### 連続推定結果 ホワイトノイズを移動させて推定させました. @[youtube](https://youtu.be/RJv6MgxWT3g) 音源を移動させると,正しく音源の位置を推定することができています. ### リアルタイム推定結果 上で行った実験(動画)は、録音データを一度PCに転送してからPythonで解析した「オフライン解析」の結果でした。 しかし、本プロジェクトの目標は「スタンドアロンなMRデバイス」です。そこで、Pythonで検証したロジックを全てC++(Arduino)で書き直し、**SPRESENSE内部で完結してリアルタイム処理するファームウェア**を作成しました。 #### 開発の壁:SRAM容量と「Result code 0xf1」 SPRESENSEで「4ch録音 (48kHz/16bit)」と「2ch再生」を同時に行おうとすると、メモリ不足で `Result code 0xf1` エラーが発生しました。 対策として、サンプリングレートを人間の音声帯域に十分な **16kHz** に落とし、さらに `Player` と `Recorder` の初期化順序を工夫することで解決しました。 #### 浮動小数点の罠:「Dist:inf」バグ PCから移植したC++コードを実行すると、全てのグリッドのパワーが `0` になる現象に遭遇しました。デバッグログを仕込んで解析したところ、マイク間距離の計算結果が `inf`(無限大)になっていました。 原因は `powf()` 関数の一部入力に対する挙動でした。これを単純な掛け算(`x * x`)に置き換えることで解消しましたが、PC(Python)と組み込み(C++)の挙動の違いに改めて気付かされました。 #### 最終動作テスト こうして完成したファームウェアを書き込み、リアルタイム動作させた様子がこちらです。 グリッド解像度も、計算リソースに余裕があったため **8x7 (56分割)** に強化しています。 @[youtube](https://youtu.be/6VYRtfoaoA0) PC画面(可視化ツール)は鏡のように向かい合って配置しているため左右が逆に見えますが、音源の移動に合わせてヒートマップの赤いピークが追従しているのが分かります。 シリアル通信の帯域制限(115200bps)により若干のラグはありますが、SPRESENSE内部の計算は数ミリ秒で完了しており、十分にリアルタイムと言えます。 # まとめ SPRESENSEの強力なマルチコアとオーディオ機能を活用することで、PCレスで動作するスタンドアロンな音源定位デバイスの実装に成功しました。 **今回の成果:** 1. **理論と実践の融合**: Pythonシミュレータで検証したDelay-and-Sum法を、C++でSPRESENSEに完全移植しました。 2. **リアルタイム性**: 16kHzサンプリング・ブロック処理・リングバッファを組み合わせることで、音飛びのないリアルタイム処理(12ms/frame)を実現しました。 3. **高解像度**: SPRESENSEの演算能力を活かし、8x7(56分割)という高解像度な空間把握が可能であることを実証しました。 現在はまだ「音の方向が見える」段階ですが、次はこの情報を使って「特定の方向の音だけを抽出して聞く(聴覚拡張)」機能の実装に進みます。 SPRESENSEなら、定位したデータを使ってフィルタリングし、そのままヘッドホンに出力することも可能なはずです! 次回:「聴覚拡張編:騒音の中で君の声だけを聞きたい」にご期待ください。