Yakatano が 2025年01月31日16時12分56秒 に編集
初版
タイトルの変更
聴覚Mixed Realityデバイスの作成①
タグの変更
SPRESENSE
mic
virtualreality
mixedreality
メイン画像の変更
記事種類の変更
製作品
ライセンスの変更
(MIT) The MIT License
本文の変更
# はじめに これまで電子工作として[isolation sphere](https://elchika.com/article/9b97a7b7-561f-4795-9e16-3e011c045913/)や[POV neon](https://tajmahal0707.hatenablog.com/entry/2022/05/17/112921)など球体のガジェットでLチカをしてきました. 今回はSPRESENSEのコンテストもあるので,そろそろ球体から離れて別のものを作ろうと色々考えてみました.(Lチカもそろそろ卒業したい) ### SPREENSEでなにつくろ? 球体ガジェットでもSPRESENSEを使ってきたのですが,今回新たにプロジェクトを立ち上げると言うことでSPRESENSEならではのガジェットを作ろうと考えてみます. 私の中のSPRESENSEのイメージ ・6コア強い ・カメラ機能強い ・音響機能強い と,この中で新たなチャレンジとして採用したのが私が今までトライしたことのなかった音響系のガジェットでした. 実は以前から研究で携わっていたvirtual RealityやMixed Realityに関するガジェットネタがあり,それを作ろうと思い立ったのです. ちょっと足の長い話になりそうなので,頑張ってやっていきます # 聴覚Mixed Realityデバイス 私はかつての職場でVirtual RealityやMixed Realityの研究・開発を行っていました.HMD(Head-Mounted Display)やら視覚系の研究が多い中,一緒に研究していたメンバーとこんな話をしたことがあります. ##### 視覚系のHMDに対して聴覚系のHMDに相当するものってどんな構成・機能になるだろう? その時もいろいろなアイデアが出て「面白そうだ」と温めていたのでした. ### 視覚版HMD そもそもHMDとはどんなものでしょう? - [ビデオシースルー型とは?VR/AR/MRにおける3つのHMDディスプレイタイプを解説](https://protrude.com/report/video-see-through-202101/#:~:text=%E5%85%89%E5%AD%A6%E3%82%B7%E3%83%BC%E3%82%B9%E3%83%AB%E3%83%BC%E5%9E%8B%E3%83%87%E3%82%A3%E3%82%B9%E3%83%97%E3%83%AC%E3%82%A4,%E3%81%84%E3%82%8B%E3%81%A8%E3%81%84%E3%81%88%E3%82%8B%E3%81%A7%E3%81%97%E3%82%87%E3%81%86%E3%80%82) - [ビデオシースルー方式と光学シースルー方式って何が違うの?【知っておきたいXRの専門用語】](https://www.xr-lifedig.com/beginner/240509_01) - [Apple Vision Proにみるビデオシースルー型HMDと光学式ARグラスの比較・考察](https://speakerdeck.com/kotauchisunsun/apple-vision-pronimirubideosisuruxing-hmdtoguang-xue-shi-argurasunobi-jiao-kao-cha) - [現実空間とCGがシームレスに融合する世界:MR(複合現実)システム](https://global.canon/ja/technology/mr2019.html) 上の記事のようにHMDには大きく分けて3つの種類があります.(細かい説明は上のリンクに譲ります) - 完全没入型HMD - 外界を見ることができないディスプレイのみのHMD - [meta quest](https://www.amazon.co.jp/Meta-Quest-128GB-VR%E3%83%98%E3%83%83%E3%83%89%E3%82%BB%E3%83%83%E3%83%88-%E3%82%B4%E3%83%BC%E3%82%B0%E3%83%AB/dp/B09B9F7439) - [VIVE](https://www.vive.com/jp/) - [参考](https://www.biccamera.com/bc/i/topics/osusume_hmd/index.jsp) - Optical see-through HMD - 通常のメガネにハーフミラーを設置して,ディスプレイの映像と現実の映像を重ね合わせることで,現実視野に仮想を重畳する方式.仮想物が半透明になってしまう点などが課題だが,軽量・ロングバッテリーが利点 - [EPSON BT-300](https://www.epson.jp/support/portal/support_menu/bt-300.htm) - [Hololens](https://learn.microsoft.com/ja-jp/hololens/) - [Renovo](https://www.lenovojp.com/business/special/174/) - [参考](https://xtech.nikkei.com/atcl/nxt/mag/nmc/18/00041/00007/) - Video see-through HMD - Optical see-throughと異なり外界の情報をビデオカメラで取り込みビデオ画像上にCGを重畳することでXR空間を構成する.必ず視野画像に時間遅れが発生する,消費電力が大きい点などが課題だが,リアルな呈示が可能 - [CANON](https://www.canon-its.co.jp/solution/industry/manufacturing/xr/mr/mreal-display) - [SONY](https://news.mynavi.jp/article/20230518-2682266/) - [Apple](https://www.apple.com/jp/apple-vision-pro/) ### 視覚→聴覚 ここでこの視覚呈示デバイスであるHMDのスキームを聴覚デバイスに置き換えてみましょう. - 完全没入型HMD - これはステレオヘッドフォンそのものですね.しかもノイズキャンセリング機能付きであればさらに高性能. 外界の音を遮断し,生成した仮想音場を再現する.ステレオで再生できるので,音像の立体化も可能です.[バイノーラルステレオ](https://www.google.com/search?q=%E3%83%90%E3%82%A4%E3%83%8E%E3%83%BC%E3%83%A9%E3%83%AB%E3%82%B9%E3%83%86%E3%83%AC%E3%82%AA&oq=%E3%83%90%E3%82%A4%E3%83%8E%E3%83%BC%E3%83%A9%E3%83%AB%E3%82%B9%E3%83%86%E3%83%AC%E3%82%AA&gs_lcrp=EgZjaHJvbWUyBggAEEUYOdIBCDQxOTZqMGo3qAIAsAIA&sourceid=chrome&ie=UTF-8)やSONYの[360 Virtual Mixing Environment](https://www.minet.jp/brand/sony-360-vme/sony-360-vitual-mixing-environment/),おなじくSONYの[360 Reality Audio](https://www.sony.jp/headphone/special/360_Reality_Audio/)など閉じた(外界と遮断した)環境の中で3次元の音場を作って呈示する方法です. - see-through型HMD - 外部環境と仮想環境を組み合わせて呈示する方式です. - Optical see-throughに対応するものは,外音を取り入れることができる方式.最近発売されてきているオープンイヤー型のヘッドフォンなどがそれに当たるかもしれません.[nwm One](https://nwm.global/products/one)  オープンイヤーなのでそのまま外音が耳の中に入ってきます. ただしこの方法では外界のreal worldの音場を改変できないと言う欠点があります.視覚版と同じようにそのまま外音が耳に入ってくるのでその音を消すことが難しいです. - Video see-throughに対応するものは,通常の密閉型ヘッドフォンを用いる点は完全没入型と同じです.しかしsee-throughするためにHMDのカメラに相当するものとしてマイクを取り付ける方式です. ノイズキャンセリング機能がついているものは,当然マイク搭載なので今回のaudio see-through headphoneとしては最適なものかもしれません. video see-throughは現実空間にリアルなCGオブジェクトを配置するMR(Mixed Reality)的な使い方に向いていて,optical see-throughは現実空間にアノテーションなどを表示するAR(Augumented Reality)的な使い方に向いていると考えています. 今回はvideo see-through HMDの聴覚版であるaudio see-through Headphoneに相当するデバイスの作成に挑戦してみます. ### Video see-through display 上で書いたようにビデオシースルー型のHMDはApple Vision Proをはじめ,近年盛んに開発されているHMDの形態です. 基本的なvideo see-throughの仕組みは以下のような構造になっています. 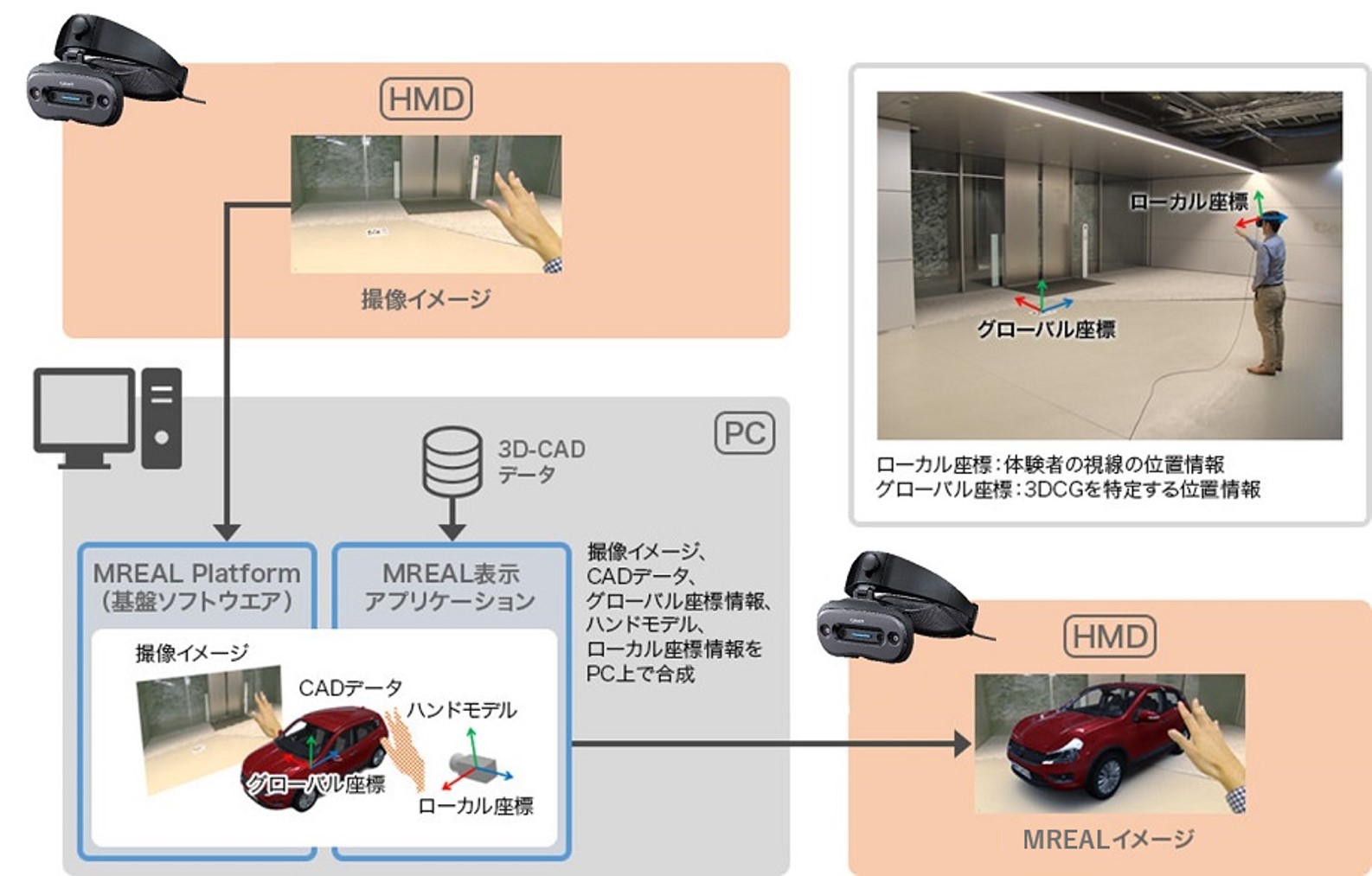 出展:https://global.canon/ja/technology/mr2019.html ### [カメラ] - [画像処理] ー [ディスプレイ] 外界(real world)をカメラで撮像し,画像を解析することで外界の3次元座標系を形成し,CGを描画する仮想空間の座標系と一致させることで現実画像の中にレンダリングしたCG物体を配置することができるという仕組みです. 一度ヒトの目に入ってくる情報を遮断し,代わりにカメラで撮影したリアル空間仮想空間とを組み合わせ,加工してディスプレイに表示することでMRを実現することができます. では,この構成を聴覚として構成し直すとどうなるでしょうか? - カメラ→マイク 聴覚にとってカメラに相当するものがマイクです.外界の音場を取得します.HMDと同じようにステレオ(以上)であることで立体音場を獲得できます.今回は4ch使用する予定 - ディスプレイ→スピーカー ディスプレイに相当するものがスピーカーというかヘッドフォンになります. Bluetoothでも良いのですが,SPRESENSEと接続することを考えると有線接続できるデバイスが望ましいです. 同時にノイズキャンセリング機能があれば外界の音を遮断することができるので,理想的な構成になるかもしれません.そうでなくても密閉型のヘッドフォンであれば外音はかなり吸収できるでしょう. - 画像処理→音声処理 ここがまず重要な機能の一つです 大きく分けて - 音源分離機能 外界に存在する音源数を分離 - 音源定位 外界音源の位置を特定.視野角と連動すると視野角あたりの音源の有無やその位置 - (BSS)Blind Source Separation 録音された音声信号は外界の全ての音源が混在しており,その中から特定の音源の波形のみを抽出する処理 これらの処理を行うことで,例えば現実の物体から出ている音を加工したり,消したり,別の音に置き換えたりできるのではないかと期待しています. - ラジオを仮想的な瓶の中に入れてくぐもった音を出す - 特定の方向からの音を消す(もしくは小さくする) - ボールが跳ねる音をマリオの音に書き換える などできたら面白いと思いませんか? この構成の基本となるマイク→音声処理の部分をコア数が多く高速で,音声処理に強いSPRESENSEに担ってもらおうと考えています. クローズなループでまずはマイク→そのままの音声をヘッドフォンに,という流れを作りそれが安定して動くようにSPRESENSEをかまそうと思います. # 設計 ### HeadPhone 今回用意したものはこれ [ヘッドホン bluetooth ヘッドホン ワイヤレスヘッドホン Sanlao Bluetooth5.3 有線 無線両用 ヘッドフォン マイク付き](https://www.amazon.co.jp/%E3%83%AF%E3%82%A4%E3%83%A4%E3%83%AC%E3%82%B9%E3%83%98%E3%83%83%E3%83%89%E3%83%9B%E3%83%B3-Sanlao-Bluetooth5-3-%E6%9C%80%E5%A4%A720%E6%99%82%E9%96%93%E9%80%A3%E7%B6%9A%E5%86%8D%E7%94%9F-%E3%82%AA%E3%83%BC%E3%83%90%E3%83%BC%E3%82%A4%E3%83%A4%E3%83%BC%E3%83%98%E3%83%83%E3%83%89%E3%83%9B%E3%83%B3/dp/B0DGQLPYXV?__mk_ja_JP=%E3%82%AB%E3%82%BF%E3%82%AB%E3%83%8A&crid=2H5DO374KSAX1&dib=eyJ2IjoiMSJ9.AhbPExgnSJ2Nd9xn31tR7Te-VkXxSTcf2S71ekXxD7meXaVj7IdU2otMmBeeeYwKC-_jV_KLUgrfEk1iFu3UcYp3q-yddqm5PnmCEEIKOS-TY6ejh9sIfzBw8PGR5AvhtoPd2VfuqjWU9_jSSEL_qQWQiUgRv6iMhdlv1j1n4CsIj5ovrSDLOo0CWBjoXD2IuMg79k3Dr6eHHbUO_Fn1FxANYdqTNNTXbq1JyernLCtWQoYzn_KDJachb2rnLCa8ZFWa46dYTQaHvYDb_Ba3biAhOKfbKvWLQH1EUCCHfCXQdrRaMIqkOGqOy0T4vvaUtzdp2YahlvpktI5-0bl0tPJ405Oh1PdXICIAQm6Mh1ImRq5UZjhXWNoQyBKgT8VZXykKPCuMJeXIKBdbcwAxmO_Z6BCtWtItqajF2-dP3J0WYqRg-YyHd7Th3jAPt2es.MxcryU2YhS3q7dLafZzM5NRs7mxjPzmVDji1IRNutdw&dib_tag=se&keywords=%E3%83%AF%E3%82%A4%E3%83%A4%E3%83%AC%E3%82%B9%E3%83%98%E3%83%83%E3%83%89%E3%83%9B%E3%83%B3&qid=1737860311&sprefix=%E3%83%AF%E3%82%A4%E3%83%A4%E3%83%AC%E3%82%B9+%E3%83%98%E3%83%83%E3%83%89%E3%83%9B%E3%83%B3%2Caps%2C171&sr=8-5) と同等品(リンクを消失してしまいました)で,買った実物はこれです.  Bluetoothと有線を両方使用できて,ノイズキャンセリング機能付き(後でノイキャンは通話機能のみっぽいことが判明) ### SPRESENSE本体  [製品情報](https://developer.sony.com/ja/spresense#spresense-key-features) ここは説明不要だと思います. 音声処理として,BSSやビームフォーミングなど負荷の高い処理が入るので,コアも多く性能の高いSPRESENSEは向いていると思います. ### 拡張ボード  今回拡張機能は重要です. アナログマイク・デジタルマイクを複数設置できる機能があり,この拡張ボードが今回のプロジェクトの肝になると思っています. ### カメラ  このカメラは,前方の視野に対して音源を特定・分析した結果を表示できるようにするためのものです. 画像ベースで物体認識してその物体に対して音声分析を行う方式も考えられます. ### WiFiボード  画像や音声データを加工する処理を行う時や,UIでコントロールを行う際にROS2を使用できないかと考えており,そのために用意しました. ### IMU  BMI270を搭載した[9axis IMU](https://www.switch-science.com/products/9870)です. 私自身が元々[BNO055](https://akizukidenshi.com/catalog/g/g116996/)を使い慣れているのと出力にQuaternionを選択できるのでこれを採用するのか,BMI270ではオイラー角が出力されるので,そこからquaternionに変換する処理をcoreにさせる必要があり,計算リソースとして足りるのかどうかを判断する必要があります. IMUを使うことで,頭部の傾きや動きに対応した音源推定に応用することを期待しています. ....ということをチャットGPT君に指摘されて「なるほど!」となり実装を追加することにしたのでした **追記**:Qwiic接続基板ですが,これを使うとカメラケーブルと干渉するのでBMI270で行くことにしました. ### マイクの選定 今回はここが大きな課題です.私自身画像系を多く扱ってきていて音声に関しては素人なので,デジタルマイクとアナログマイクの違いもよくわからないまま始めてしまいました. [SPRESENSE マイクの使用方法](https://developer.sony.com/spresense/development-guides/hw_docs_ja.html#_%E3%83%87%E3%82%B8%E3%82%BF%E3%83%AB%E3%83%9E%E3%82%A4%E3%82%AF%E3%81%AE%E6%8E%A5%E7%B6%9A%E6%96%B9%E6%B3%95)を参考に,ChatGPTの力も借りてマイクデバイスの選定を行います. ここで話すと長いので[別の記事](https://elchika.com/article/25ef421d-f552-4357-8ec8-d5a301fd7a0c/)で書きますが,ここがすごく苦労しましたが,結果としてアナログマイクを使用することにしました.  これによって4chの音場を取得することにします. ### HMD RenovoのHMDを借りられる機会があり,解析した音場の可視化にこちらを使ってみようと考えています.   # 設計 上記の部品構成に対して各部を統合する筐体の設計を行います. ヘッドフォンのブリッジにマイクアレイを設置できるフレームを設置してマイクを配置,このフレームにカメラと本体を配置できるようにします. ### SPRESENSE 拡張ボードにSPRESENSE本体を搭載し,JP1,JP2のAdd-onにはWiFiとIMUボードが載ります. CN5にカメラ用のフラットケーブルを装着して本体への装着は完了. 電源周りはUSBケーブルから取得することにします. ちょうど[Mic&LCD KIT](https://akizukidenshi.com/catalog/g/g116589/)のケースデータが[booth](https://first-diy.booth.pm/items/3095415)にあったので,こちらを流用してケースを作成します.  これによって[Mic&LCD KIT](https://akizukidenshi.com/catalog/g/g116589/)までちょうど収まる部分の実装が完了.   全て装着するとこんな感じ. しかし今回はLCDは使用しないので除外して,こう.  SPRESENSE本体でマイクアレイから生成した音声をイヤホン端子からケーブルで直接ヘッドフォンに接続する構造に. しかし,課題が一つ. ### カメラモジュール   カメラ用フレームがHDRに対応していないようでサイズが合いません.カメラの実装はまだ先なので,今回はこのまま作業を続けることにします. それにしても,[booth](https://first-diy.booth.pm/items/3095415)のデータは今回のプロジェクトにばっちり適合していたので,自分で設計する必要がない(実は設計したんだけれど,こちらの方が性能が良いw)ので助かりました. また,本当はカメラはおそらく眉間の中央(HMDの鼻あての前)に配置するのが妥当かと思いますが,フラットケーブルの長さが足りないため,オデコの第三の眼付近に配置することになりました. ### マイクアレイフレーム  このように4chのアナログマイクを接続することができるので,立体音場を録音できるようにマイクの配置を決めていきます. マイク配置は以下の方針で - 両耳(ヘッドフォンのイヤーカフ前方)に左右2ch - 上の2chと同一直線上にならない平面上に2ch これで左右対称の台形になるのですが,左右対称の台形or非対称の台形にすることも検討してみます. 対称配置のメリット: - ビームフォーミングの計算が比較的シンプル - 左右の音源に対して同等の性能が期待できる - キャリブレーションが容易 デメリット - 特定の方向で音源の分離が困難になる可能性(左右対称な配置による制約) 非対称配置のメリット: - より多様な空間サンプリングが可能 - 特定の周波数での空間エイリアシングを低減できる可能性 - 均一な方向分解能を得やすい デメリット - ビームフォーミングの計算がやや複雑に - キャリブレーションがより重要に 結論としては,キャリブレーションの精度などより技術的なレベルが上がりそうなので,今回は左右対称台形で進めます. これを踏まえてCADで設計  ちょうどヘッドフォンのブリッジに沿うようにフレームを配置して,マイクを配置する穴を開けます.  マイクには着脱可能なクリップがあり,このクリップ部分のサイズに合わせた穴をあけて,イヤホンジャックがその穴を通らないためスリットを入れてケーブルを通すことができるようにしました.  頭頂部にSPRESENSEを配置した例がこちら   ヘッドフォンと合わせるとこんな感じ  最終イメージはこんな感じ... ごっつい..w  # 実装 設計のほうはここで一旦終了して,プログラムの実装の方に移りましょう. ## 音源分離 今回の聴覚MRは,基本構造としては音源を分離して各音源に対して加工→decodingして元に戻す,という構造です. 音源を分離する機能がキモの一つになるのですが,大きく分けて二つの方法があると考えています. - 音源を特定して分離する方法 Blind Source Separation(BSS)や物体認識など,何らかの方法で音源を特定して,その音源を分離する方法 - 音源の方向を分離する方法 ビームフォーミングなどマイクアレイの方向による差異を使って到来方向(DOA: Direction of Arrival)を推定する方法 TasNetなどDeepLearningを用いた音源分離法などもある 今回はリアルタイム性を重視しており,SPRESENSEのマルチコア能力やマイクアレイの構造からビームフォーミングを用いた方法を採用することにしてみます. - 参考資料 - [Deep-Learning-Based Environmental Sound Segmentation - Integration of Sound Source Localization, Separation, and Classification](https://www.slideshare.net/slideshow/deeplearningbased-environmental-sound-segmentation-integration-of-sound-source-localization-separation-and-classification/251994711) - [Audio Segmentation](https://www.music.mcgill.ca/~ich/classes/mumt611_07/presentations/shiyong/shiyong07audio.pdf) ### ビームフォーミング法 ビームフォーミングの基本原理は、複数のマイクで収集した音声信号の時間的遅延補正(Delay Compensation)と加重合成(Weighted Summation)を行うことで、特定の方向の音を強調することにあります。 - 音波の到達時間の違いを利用 は空気中を一定の速度(約343 m/s)で伝わるため、異なる位置に配置されたマイクに届く時間がわずかに異なります。この時間差を利用して、特定の方向からの音を強調したり、他の方向の音を抑制したりします。 - 遅延・加重処理 - 目標とする音源方向を決める。 - その方向からの音がすべてのマイクに揃って届くように時間補正(遅延)を行う。 - 遅延補正後の信号に**適切な重み付け(加重合成) **をして合成すると,時間補正した方向の音源は強め合うが,それ以外は弱め合うような合成になり,特定方向からの信号のみ強調することができる. 先に音源方向を決定するのが大きな特徴で,このことで音場内に存在する音源の数によらず一定の処理負荷にすることが可能で,今回はマイク(とカメラ)の向いている前方領域を10x10に分割し,その分割領域をそれぞれマルチコアでビームフォーミングしながら特定方向のみを強調する. beamformingの実装方法については, 1. フィルタ・サム方式(Delay-and-Sum Beamforming) 最も基本的なビームフォーミング手法です。各マイクの音声信号を適切に遅延補正し、単純に加算することで特定の方向の音を強調します。 メリット:計算がシンプルで実装が容易。 デメリット:ビームの指向性が広く、精度がそれほど高くない。 2. 最適ビームフォーミング(MVDR / Minimum Variance Distortionless Response) 目標方向の音声を歪ませずに、他の方向のノイズや干渉を最小化する手法。 メリット:ノイズ抑制効果が高い。 デメリット:リアルタイム処理の負荷が大きい。 3. 固定ビームフォーミング(Fixed Beamforming) 事前に設定された方向に対して固定的な指向性を持たせる方法。 メリット:計算コストが低く、実装が簡単。 デメリット:音源が移動すると適切に対応できない。 4. 適応ビームフォーミング(Adaptive Beamforming) 音源の位置が変化しても、自動的に最適なビームパターンを形成する手法(例:LMSアルゴリズムやRLSアルゴリズムを使用)。 メリット:動的な音源に対応可能。 デメリット:計算コストが高い。 とあるが,今回は台形マイクアレイの前方を10x10のパッチに分割した方向ごとに分離する手法を取るので,3の固定ビームフォーミング方式を採用することにする. ## マイク機能の実装 マイクについては,製造元のAutolabさんのgithubがあります. [Github](https://github.com/autolab-fujiwaratakayoshi/) 4chアナログマイクの入力をFFTするサンプルが記載されているのでこれを参考にします. パッチベースのbeamformingの実装例がこんな感じ ```// パッチベースのビームフォーミング実装例 struct Patch { float center_x; float center_y; float center_z; float power; // 音響パワー bool is_sound_source; // 音源の有無 }; class PatchBeamforming { private: static const int PATCH_X = 10; // X方向のパッチ数 static const int PATCH_Y = 10; // Y方向のパッチ数 Patch patches[PATCH_X][PATCH_Y]; float threshold; // 音源判定の閾値 public: void initializePatches() { // カメラの画角に基づいてパッチの中心座標を計算 float x_step = camera_fov_x / PATCH_X; float y_step = camera_fov_y / PATCH_Y; for (int i = 0; i < PATCH_X; i++) { for (int j = 0; j < PATCH_Y; j++) { patches[i][j].center_x = x_step * (i + 0.5); patches[i][j].center_y = y_step * (j + 0.5); patches[i][j].center_z = focal_distance; // 焦点距離 } } } void processAudioFrame(AudioFrameClass &audio_frame) { // 各パッチに対してビームフォーミングを実行 for (int i = 0; i < PATCH_X; i++) { for (int j = 0; j < PATCH_Y; j++) { // パッチの中心に向けてビームフォーミング float power = calculateBeamPower( audio_frame, patches[i][j].center_x, patches[i][j].center_y, patches[i][j].center_z ); patches[i][j].power = power; patches[i][j].is_sound_source = (power > threshold); } } } std::vector<Patch> detectSoundSources() { std::vector<Patch> sound_sources; // 局所的な極大値を探索 for (int i = 1; i < PATCH_X - 1; i++) { for (int j = 1; j < PATCH_Y - 1; j++) { if (isLocalMaximum(i, j)) { sound_sources.push_back(patches[i][j]); } } } return sound_sources; } }; ``` ## メモリの管理 今回のプロジェクトでは,リングバッファを用いた方法が効果的かと考えています. そこでリングバッファの実装も試してみました. ```#define BUFFER_SIZE 1024 // バッファのサイズ struct RingBuffer { float buffer[BUFFER_SIZE]; // オーディオデータ用バッファ int head; // 書き込み位置 int tail; // 読み込み位置 int count; // 格納されているデータ数 }; void initRingBuffer(RingBuffer *rb) { rb->head = 0; rb->tail = 0; rb->count = 0; } // データを追加(書き込み) bool pushData(RingBuffer *rb, float value) { if (rb->count == BUFFER_SIZE) { return false; // バッファが満杯 } rb->buffer[rb->head] = value; rb->head = (rb->head + 1) % BUFFER_SIZE; rb->count++; return true; } // データを取得(読み込み) bool popData(RingBuffer *rb, float *value) { if (rb->count == 0) { return false; // バッファが空 } *value = rb->buffer[rb->tail]; rb->tail = (rb->tail + 1) % BUFFER_SIZE; rb->count--; return true; } ``` # まとめ ここまで実装して時間切れになってしまいました. - 聴覚MRデバイスの基本構成の決定 - 検討用の装着デバイスの試作Ver1.0の作成 - 基本的なbeamforming,ring bufferの試験実装 など聴覚MRデバイスのPoCとしてプロジェクトがスタートしました. 最初のデジタル/アナログマイク選定のあたりでかなり時間をとってしまったり,いい機会なのでとchatgptなどの生成AIをベースにした開発を検討していろいろやったりとしていました. このプロジェクトは,冒頭でも話した通り,私がMRの研究を行っていた頃に同僚とふとした雑談で出てきた話です. それから10年ほど経ってしまっていますが,いまだに頭の片隅に残っていたものでした. 「SPRESENSEを使って何をしよう?」 となった時に頭の中で真っ先に浮かんだのもこれでした. 音声処理など全く知識のない状態からBSS,音声分離,そしてビームフォーミングと色々と勉強できて楽しい時間でした. これからは実装フェーズに入るので理論的な検討はいったんストップですが,楽しかったです. 次からの実装も楽しいので,頑張って進めていきます.